5 Data Manipulation with dplyr
https://learn.datacamp.com/courses/data-manipulation-with-dplyr
Main functions and concepts covered in this BP chapter:
- Understanding your data
- Selecting columns
- Arranging observations
- The
filter()andarrange()verbs- Filtering for conditions
- Filtering and arranging
- The
mutate()verb- Calculating the number of government employees
- Calculating the percentage of women in a county
Mutate(),filter(), andarrange()- The
count()verb- Counting by region
- Counting citizens by state
- Mutating and counting
- The
group_by(),summarize(), andungroup()verbs- Summarizing
- Summarizing by state
- Summarizing by state and region
- The
slice_minandslice_maxverbs- Selecting a county from each region
- Finding the lowest-income state in each region
- Using
summarize,slice_max, andcounttogether - Selecting
- Selecting columns
- Select helpers
- The
renameverb- Renaming a column after count
- Renaming a column as part of a select
- The relocate verb
- Using relocate
- Choosing among the four verbs
- Filtering and arranging for one year
- Finding the most popular names each year
- Visualizing names with ggplot2
- Grouped mutates
- Finding the year each name is most common
- Adding the total and maximum for each name
- Visualizing the normalized change in popularity
- Window functions
- Using ratios to describe the frequency of a name
- Biggest jumps in a name
Packages used in this chapter:
## Load all packages used in this chapter
library(tidyverse) #includes dplyr, ggplot2, and other common packages## ── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
## ✔ dplyr 1.1.4 ✔ readr 2.1.4
## ✔ forcats 1.0.0 ✔ stringr 1.5.1
## ✔ ggplot2 3.4.4 ✔ tibble 3.2.1
## ✔ lubridate 1.9.3 ✔ tidyr 1.3.0
## ✔ purrr 1.0.2
## ── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
## ✖ dplyr::filter() masks stats::filter()
## ✖ dplyr::lag() masks stats::lag()
## ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errorsDatasets used in this chapter:
## Load datasets used in this chapter
counties <- read_rds("data/counties.rds")
babynames <- read_rds("data/babynames.rds")Tip: don’t forget the pipe (%>%) between each step
5.1 Transforming Data with dplyr
5.1.1 Understanding your data
Take a look at the counties dataset using the glimpse() function.
Q: What is the first value in the income variable?
A: 51281
## Rows: 3,138
## Columns: 40
## $ census_id <chr> "1001", "1003", "1005", "1007", "1009", "1011", "10…
## $ state <chr> "Alabama", "Alabama", "Alabama", "Alabama", "Alabam…
## $ county <chr> "Autauga", "Baldwin", "Barbour", "Bibb", "Blount", …
## $ region <chr> "South", "South", "South", "South", "South", "South…
## $ metro <chr> "Metro", "Metro", "Nonmetro", "Metro", "Metro", "No…
## $ population <dbl> 55221, 195121, 26932, 22604, 57710, 10678, 20354, 1…
## $ men <dbl> 26745, 95314, 14497, 12073, 28512, 5660, 9502, 5627…
## $ women <dbl> 28476, 99807, 12435, 10531, 29198, 5018, 10852, 603…
## $ hispanic <dbl> 2.6, 4.5, 4.6, 2.2, 8.6, 4.4, 1.2, 3.5, 0.4, 1.5, 7…
## $ white <dbl> 75.8, 83.1, 46.2, 74.5, 87.9, 22.2, 53.3, 73.0, 57.…
## $ black <dbl> 18.5, 9.5, 46.7, 21.4, 1.5, 70.7, 43.8, 20.3, 40.3,…
## $ native <dbl> 0.4, 0.6, 0.2, 0.4, 0.3, 1.2, 0.1, 0.2, 0.2, 0.6, 0…
## $ asian <dbl> 1.0, 0.7, 0.4, 0.1, 0.1, 0.2, 0.4, 0.9, 0.8, 0.3, 0…
## $ pacific <dbl> 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0…
## $ citizens <dbl> 40725, 147695, 20714, 17495, 42345, 8057, 15581, 88…
## $ income <dbl> 51281, 50254, 32964, 38678, 45813, 31938, 32229, 41…
## $ income_err <dbl> 2391, 1263, 2973, 3995, 3141, 5884, 1793, 925, 2949…
## $ income_per_cap <dbl> 24974, 27317, 16824, 18431, 20532, 17580, 18390, 21…
## $ income_per_cap_err <dbl> 1080, 711, 798, 1618, 708, 2055, 714, 489, 1366, 15…
## $ poverty <dbl> 12.9, 13.4, 26.7, 16.8, 16.7, 24.6, 25.4, 20.5, 21.…
## $ child_poverty <dbl> 18.6, 19.2, 45.3, 27.9, 27.2, 38.4, 39.2, 31.6, 37.…
## $ professional <dbl> 33.2, 33.1, 26.8, 21.5, 28.5, 18.8, 27.5, 27.3, 23.…
## $ service <dbl> 17.0, 17.7, 16.1, 17.9, 14.1, 15.0, 16.6, 17.7, 14.…
## $ office <dbl> 24.2, 27.1, 23.1, 17.8, 23.9, 19.7, 21.9, 24.2, 26.…
## $ construction <dbl> 8.6, 10.8, 10.8, 19.0, 13.5, 20.1, 10.3, 10.5, 11.5…
## $ production <dbl> 17.1, 11.2, 23.1, 23.7, 19.9, 26.4, 23.7, 20.4, 24.…
## $ drive <dbl> 87.5, 84.7, 83.8, 83.2, 84.9, 74.9, 84.5, 85.3, 85.…
## $ carpool <dbl> 8.8, 8.8, 10.9, 13.5, 11.2, 14.9, 12.4, 9.4, 11.9, …
## $ transit <dbl> 0.1, 0.1, 0.4, 0.5, 0.4, 0.7, 0.0, 0.2, 0.2, 0.2, 0…
## $ walk <dbl> 0.5, 1.0, 1.8, 0.6, 0.9, 5.0, 0.8, 1.2, 0.3, 0.6, 1…
## $ other_transp <dbl> 1.3, 1.4, 1.5, 1.5, 0.4, 1.7, 0.6, 1.2, 0.4, 0.7, 1…
## $ work_at_home <dbl> 1.8, 3.9, 1.6, 0.7, 2.3, 2.8, 1.7, 2.7, 2.1, 2.5, 1…
## $ mean_commute <dbl> 26.5, 26.4, 24.1, 28.8, 34.9, 27.5, 24.6, 24.1, 25.…
## $ employed <dbl> 23986, 85953, 8597, 8294, 22189, 3865, 7813, 47401,…
## $ private_work <dbl> 73.6, 81.5, 71.8, 76.8, 82.0, 79.5, 77.4, 74.1, 85.…
## $ public_work <dbl> 20.9, 12.3, 20.8, 16.1, 13.5, 15.1, 16.2, 20.8, 12.…
## $ self_employed <dbl> 5.5, 5.8, 7.3, 6.7, 4.2, 5.4, 6.2, 5.0, 2.8, 7.9, 4…
## $ family_work <dbl> 0.0, 0.4, 0.1, 0.4, 0.4, 0.0, 0.2, 0.1, 0.0, 0.5, 0…
## $ unemployment <dbl> 7.6, 7.5, 17.6, 8.3, 7.7, 18.0, 10.9, 12.3, 8.9, 7.…
## $ land_area <dbl> 594.44, 1589.78, 884.88, 622.58, 644.78, 622.81, 77…5.1.2 Selecting columns
Select the following four columns from the counties variable:
state
county
population
poverty
## # A tibble: 3,138 × 4
## state county population poverty
## <chr> <chr> <dbl> <dbl>
## 1 Alabama Autauga 55221 12.9
## 2 Alabama Baldwin 195121 13.4
## 3 Alabama Barbour 26932 26.7
## 4 Alabama Bibb 22604 16.8
## 5 Alabama Blount 57710 16.7
## 6 Alabama Bullock 10678 24.6
## 7 Alabama Butler 20354 25.4
## 8 Alabama Calhoun 116648 20.5
## 9 Alabama Chambers 34079 21.6
## 10 Alabama Cherokee 26008 19.2
## # ℹ 3,128 more rows5.1.3 Arranging observations
Here you see the counties_selected dataset with a few interesting variables selected. These variables: private_work, public_work, self_employed describe whether people work for the government, for private companies, or for themselves.
Add a verb to sort the observations of the public_work variable in descending order.
counties_selected <- counties %>%
select(state, county, population, private_work, public_work, self_employed)
counties_selected %>%
# Add a verb to sort in descending order of public_work
arrange(desc(public_work))## # A tibble: 3,138 × 6
## state county population private_work public_work self_employed
## <chr> <chr> <dbl> <dbl> <dbl> <dbl>
## 1 Hawaii Kalawao 85 25 64.1 10.9
## 2 Alaska Yukon-Koyukuk… 5644 33.3 61.7 5.1
## 3 Wisconsin Menominee 4451 36.8 59.1 3.7
## 4 North Dakota Sioux 4380 32.9 56.8 10.2
## 5 South Dakota Todd 9942 34.4 55 9.8
## 6 Alaska Lake and Peni… 1474 42.2 51.6 6.1
## 7 California Lassen 32645 42.6 50.5 6.8
## 8 South Dakota Buffalo 2038 48.4 49.5 1.8
## 9 South Dakota Dewey 5579 34.9 49.2 14.7
## 10 Texas Kenedy 565 51.9 48.1 0
## # ℹ 3,128 more rows5.1.4 The filter() and arrange() verbs
5.1.4.1 Filtering for conditions
You use the filter() verb to get only observations that match a particular condition, or match multiple conditions.
Find only the counties that have a population above one million (1000000).
counties_selected <- counties %>%
select(state, county, population)
counties_selected %>%
# Filter for counties with a population above 1000000
filter(population > 1000000)## # A tibble: 41 × 3
## state county population
## <chr> <chr> <dbl>
## 1 Arizona Maricopa 4018143
## 2 California Alameda 1584983
## 3 California Contra Costa 1096068
## 4 California Los Angeles 10038388
## 5 California Orange 3116069
## 6 California Riverside 2298032
## 7 California Sacramento 1465832
## 8 California San Bernardino 2094769
## 9 California San Diego 3223096
## 10 California Santa Clara 1868149
## # ℹ 31 more rowsWe can filter 2 things at once. Find only the counties in the state of California that also have a population above one million (1000000).
counties_selected <- counties %>%
select(state, county, population)
counties_selected %>%
# Filter for counties with a population above 1000000
filter(state == "California", population > 1000000)## # A tibble: 9 × 3
## state county population
## <chr> <chr> <dbl>
## 1 California Alameda 1584983
## 2 California Contra Costa 1096068
## 3 California Los Angeles 10038388
## 4 California Orange 3116069
## 5 California Riverside 2298032
## 6 California Sacramento 1465832
## 7 California San Bernardino 2094769
## 8 California San Diego 3223096
## 9 California Santa Clara 18681495.1.4.2 Filtering and arranging
We’re often interested in both filtering and sorting a dataset, to focus on observations of particular interest to you. Here, you’ll find counties that are extreme examples of what fraction of the population works in the private sector. Filter for counties in the state of Texas that have more than ten thousand people (10000), and sort them in descending order of the percentage of people employed in private work.
counties_selected <- counties %>%
select(state, county, population, private_work, public_work, self_employed)
# Filter for Texas and more than 10000 people; sort in descending order of private_work
counties_selected %>%
# Filter for Texas and more than 10000 people
filter(state == "Texas", population > 10000) %>%
# Sort in descending order of private_work
arrange(desc(private_work))## # A tibble: 169 × 6
## state county population private_work public_work self_employed
## <chr> <chr> <dbl> <dbl> <dbl> <dbl>
## 1 Texas Gregg 123178 84.7 9.8 5.4
## 2 Texas Collin 862215 84.1 10 5.8
## 3 Texas Dallas 2485003 83.9 9.5 6.4
## 4 Texas Harris 4356362 83.4 10.1 6.3
## 5 Texas Andrews 16775 83.1 9.6 6.8
## 6 Texas Tarrant 1914526 83.1 11.4 5.4
## 7 Texas Titus 32553 82.5 10 7.4
## 8 Texas Denton 731851 82.2 11.9 5.7
## 9 Texas Ector 149557 82 11.2 6.7
## 10 Texas Moore 22281 82 11.7 5.9
## # ℹ 159 more rows5.1.5 The mutate() verb
Datasets don’t always have the variables we need. We can use the mutate() verb to add new variables or change existing variables.
5.1.5.1 Calculating the number of government employees
In the datacamp video, you used the unemployment variable, which is a percentage, to calculate the number of unemployed people in each county. In this exercise, you’ll do the same with another percentage variable: public_work. Use mutate() to add a column called public_workers to the dataset, with the number of people employed in public (government) work. Then sort the new column in descending order.
counties_selected <- counties %>%
select(state, county, population, public_work)
counties_selected %>%
# Add a new column public_workers with the number of people employed in public work
mutate(public_workers = public_work * population / 100) %>%
# Sort in descending order of the public_workers column
arrange(desc(public_workers))## # A tibble: 3,138 × 5
## state county population public_work public_workers
## <chr> <chr> <dbl> <dbl> <dbl>
## 1 California Los Angeles 10038388 11.5 1154415.
## 2 Illinois Cook 5236393 11.5 602185.
## 3 California San Diego 3223096 14.8 477018.
## 4 Arizona Maricopa 4018143 11.7 470123.
## 5 Texas Harris 4356362 10.1 439993.
## 6 New York Kings 2595259 14.4 373717.
## 7 California San Bernardino 2094769 16.7 349826.
## 8 California Riverside 2298032 14.9 342407.
## 9 California Sacramento 1465832 21.8 319551.
## 10 California Orange 3116069 10.2 317839.
## # ℹ 3,128 more rows5.1.5.2 Calculating the percentage of women in a county
The dataset includes columns for the total number (not percentage) of men and women in each county. You could use this, along with the population variable, to compute the fraction of men (or women) within each county. Select the columns state, county, population, men, and women. Add a new variable called proportion_women with the fraction of the county’s population made up of women.
counties_selected <- counties %>%
# Select the columns state, county, population, men, and women
select(state, county, population, men, women)
counties_selected %>%
# Calculate proportion_women as the fraction of the population made up of women
mutate(proportion_women = women / (men + women))## # A tibble: 3,138 × 6
## state county population men women proportion_women
## <chr> <chr> <dbl> <dbl> <dbl> <dbl>
## 1 Alabama Autauga 55221 26745 28476 0.516
## 2 Alabama Baldwin 195121 95314 99807 0.512
## 3 Alabama Barbour 26932 14497 12435 0.462
## 4 Alabama Bibb 22604 12073 10531 0.466
## 5 Alabama Blount 57710 28512 29198 0.506
## 6 Alabama Bullock 10678 5660 5018 0.470
## 7 Alabama Butler 20354 9502 10852 0.533
## 8 Alabama Calhoun 116648 56274 60374 0.518
## 9 Alabama Chambers 34079 16258 17821 0.523
## 10 Alabama Cherokee 26008 12975 13033 0.501
## # ℹ 3,128 more rows5.1.6 Mutate(), filter(), and arrange()
In this exercise, you’ll put together everything you’ve learned in this chapter (select(), mutate(), filter() and arrange()), to find the counties with the highest proportion of men. Select the state, county, and population columns, and add a proportion_men column with the fractional male population using a single verb. Filter for counties with a population of at least ten thousand (10000). Arrange counties in descending order of their proportion of men.
Hint: use .keep = "none" to get rid of all extra columns.
counties %>%
# Keep state, county, and population, and add proportion_men
mutate(state, county, population, proportion_men = men / population, .keep = "none") %>%
# Filter for population of at least 10,000
filter(population >= 10000) %>%
# Arrange proportion of men in descending order
arrange(desc(proportion_men))## # A tibble: 2,437 × 4
## state county population proportion_men
## <chr> <chr> <dbl> <dbl>
## 1 Virginia Sussex 11864 0.685
## 2 California Lassen 32645 0.668
## 3 Georgia Chattahoochee 11914 0.666
## 4 Louisiana West Feliciana 15415 0.664
## 5 Florida Union 15191 0.647
## 6 Texas Jones 19978 0.633
## 7 Missouri DeKalb 12782 0.632
## 8 Texas Madison 13838 0.625
## 9 Virginia Greensville 11760 0.621
## 10 Texas Anderson 57915 0.612
## # ℹ 2,427 more rows5.2 Aggregating Data
So far in this course, we’ve learned to select variables from a dataset, to filter and sort observations, and to create new variables with the mutate verb. But, so far, we’ve been working at the same level as the initial data, where every observation corresponds to one US county. In this chapter, you’ll learn to aggregate data, that is, to take many observations and summarize them into one. This is a common strategy for making datasets manageable and interpretable.
5.2.1 The count() verb
One way we can aggregate data is to count it: to find out the number of observations. The dplyr verb for this is count().
5.2.1.1 Counting by region
The counties dataset contains columns for region, state, population, and the number of citizens, which we selected and saved as the counties_selected table. In this exercise, you’ll focus on the region column.
Use count() to find the number of counties in each region, using a second argument to sort in descending order.
#Create counties_selected2
counties_selected2 <- counties %>%
select(county, region, state, population, citizens)
# Use count to find the number of counties in each region
counties_selected2 %>%
count(region, sort=TRUE)## # A tibble: 4 × 2
## region n
## <chr> <int>
## 1 South 1420
## 2 North Central 1054
## 3 West 447
## 4 Northeast 2175.2.1.2 Counting citizens by state
You can weigh your count by particular variables rather than finding the number of counties. In this case, you’ll find the number of citizens in each state. Count the number of counties in each state, weighted based on the citizens column, and sorted in descending order.
# Find number of counties per state, weighted by citizens, sorted in descending order
counties_selected2 %>%
count(state, wt=citizens, sort=TRUE)## # A tibble: 50 × 2
## state n
## <chr> <dbl>
## 1 California 24280349
## 2 Texas 16864864
## 3 Florida 13933052
## 4 New York 13531404
## 5 Pennsylvania 9710416
## 6 Illinois 8979999
## 7 Ohio 8709050
## 8 Michigan 7380136
## 9 North Carolina 7107998
## 10 Georgia 6978660
## # ℹ 40 more rows5.2.1.3 Mutating and counting
You can combine multiple verbs together to answer increasingly complicated questions of your data. For example: “What are the US states where the most people walk to work?” You’ll use the walk column, which offers a percentage of people in each county that walk to work, to add a new column and count based on it.
Use mutate() to calculate and add a column called population_walk, containing the total number of people who walk to work in a county.
Use a (weighted and sorted) count() to find the total number of people who walk to work in each state.
# Save new data set
counties_selected3 <- counties %>%
select(county, region, state, population, walk)
counties_selected3 %>%
# Add population_walk containing the total number of people who walk to work
mutate(population_walk = population * walk / 100) %>%
# Count weighted by the new column, sort in descending order
count(state, wt = population_walk, sort = TRUE)## # A tibble: 50 × 2
## state n
## <chr> <dbl>
## 1 New York 1237938.
## 2 California 1017964.
## 3 Pennsylvania 505397.
## 4 Texas 430783.
## 5 Illinois 400346.
## 6 Massachusetts 316765.
## 7 Florida 284723.
## 8 New Jersey 273047.
## 9 Ohio 266911.
## 10 Washington 239764.
## # ℹ 40 more rows5.2.2 The group_by(), summarize(), and ungroup() verbs
We’ve learned about to aggregate data using the count() verb, but count() is a special case of a more general set of verbs: group_by and summarize.
5.2.2.1 Summarizing
The summarize() verb is very useful for collapsing a large dataset into a single observation. Summarize the counties data set to find the following columns: min_population (with the smallest population), max_unemployment (with the maximum unemployment), and average_income (with the mean of the income variable).
# Save new dataset
counties_selected4 <- counties %>%
select(county, population, income, unemployment)
counties_selected4 %>%
# Summarize to find minimum population, maximum unemployment, and average income
summarize(min_population = min(population), max_unemployment = max(unemployment), average_income = mean(income))## # A tibble: 1 × 3
## min_population max_unemployment average_income
## <dbl> <dbl> <dbl>
## 1 85 29.4 46832.5.2.2.2 Summarizing by state
Another interesting column is land_area, which shows the land area in square miles. Here, you’ll summarize both population and land area by state, with the purpose of finding the density (in people per square miles). Group the data by state, and summarize to create the columns total_area (the total land_area in square miles) and total_population (with total population).
# Save new data set
counties_selected5 <- counties %>%
select(state, county, population, land_area)
counties_selected5 %>%
# Group by state
group_by(state) %>%
# Find the total area and population
summarize(total_area = sum(land_area), total_population = sum(population) )## # A tibble: 50 × 3
## state total_area total_population
## <chr> <dbl> <dbl>
## 1 Alabama 50645. 4830620
## 2 Alaska 553560. 725461
## 3 Arizona 113594. 6641928
## 4 Arkansas 52035. 2958208
## 5 California 155779. 38421464
## 6 Colorado 103642. 5278906
## 7 Connecticut 4842. 3593222
## 8 Delaware 1949. 926454
## 9 Florida 53625. 19645772
## 10 Georgia 57514. 10006693
## # ℹ 40 more rowsAdd a density column containing the total population per square mile, using the columns you already created, then arrange in descending order.
counties_selected5 %>%
group_by(state) %>%
summarize(total_area = sum(land_area),
total_population = sum(population)) %>%
# Add a density column
mutate(density = total_population / total_area) %>%
# Sort by density in descending order
arrange(desc(density))## # A tibble: 50 × 4
## state total_area total_population density
## <chr> <dbl> <dbl> <dbl>
## 1 New Jersey 7354. 8904413 1211.
## 2 Rhode Island 1034. 1053661 1019.
## 3 Massachusetts 7800. 6705586 860.
## 4 Connecticut 4842. 3593222 742.
## 5 Maryland 9707. 5930538 611.
## 6 Delaware 1949. 926454 475.
## 7 New York 47126. 19673174 417.
## 8 Florida 53625. 19645772 366.
## 9 Pennsylvania 44743. 12779559 286.
## 10 Ohio 40861. 11575977 283.
## # ℹ 40 more rows5.2.2.3 Summarizing by state and region
You can group by multiple columns instead of grouping by one. Here, you’ll practice aggregating by state and region, and notice how useful it is for performing multiple aggregations in a row.
Summarize to find the total population, as a column called total_pop, in each combination of region and state, grouped in that order.
#Save new data set
counties_selected6 <- counties %>%
select(region, state, county, population)
counties_selected6 %>%
# Group and summarize to find the total population
group_by(region, state) %>%
summarize(total_pop = sum(population))## `summarise()` has grouped output by 'region'. You can override using the
## `.groups` argument.## # A tibble: 50 × 3
## # Groups: region [4]
## region state total_pop
## <chr> <chr> <dbl>
## 1 North Central Illinois 12873761
## 2 North Central Indiana 6568645
## 3 North Central Iowa 3093526
## 4 North Central Kansas 2892987
## 5 North Central Michigan 9900571
## 6 North Central Minnesota 5419171
## 7 North Central Missouri 6045448
## 8 North Central Nebraska 1869365
## 9 North Central North Dakota 721640
## 10 North Central Ohio 11575977
## # ℹ 40 more rowsNotice the tibble is still grouped by region; use another summarize() step to calculate two new columns: the average state population in each region (average_pop) and the median state population in each region (median_pop).
counties_selected6 %>%
# Group and summarize to find the total population
group_by(region, state) %>%
summarize(total_pop = sum(population)) %>%
# Calculate the average_pop and median_pop columns
summarize(average_pop = mean(total_pop), median_pop = median(total_pop))## `summarise()` has grouped output by 'region'. You can override using the
## `.groups` argument.## # A tibble: 4 × 3
## region average_pop median_pop
## <chr> <dbl> <dbl>
## 1 North Central 5627687. 5580644
## 2 Northeast 6221058. 3593222
## 3 South 7370486 4804098
## 4 West 5722755. 27986365.2.3 The slice_min and slice_max verbs
What if instead of aggregating each state, we wanted to find only the largest or smallest counties in each state? dplyr’s slice_min and slice_max verbs allow us to extract the most extreme observations from each group.
5.2.3.1 Selecting a county from each region
Previously, you used the walk column, which offers a percentage of people in each county that walk to work, to add a new column and count to find the total number of people who walk to work in each county. Find the county in each region with the highest percentage of citizens who walk to work.
# Save new data set
counties_selected7 <- counties %>%
select(region, state, county, metro, population, walk)
counties_selected7 %>%
# Group by region
group_by(region) %>%
# Find the county with the highest percentage of people who walk to work
slice_max(walk, n = 1)## # A tibble: 4 × 6
## # Groups: region [4]
## region state county metro population walk
## <chr> <chr> <chr> <chr> <dbl> <dbl>
## 1 North Central North Dakota McIntosh Nonmetro 2759 17.5
## 2 Northeast New York New York Metro 1629507 20.7
## 3 South Virginia Lexington city Nonmetro 7071 31.7
## 4 West Alaska Aleutians East Borough Nonmetro 3304 71.25.2.3.2 Finding the lowest-income state in each region
You’ve been learning to combine multiple dplyr verbs together. Here, you’ll combine group_by(), summarize(), and slice_min() to find the state in each region with the highest income.
When you group by multiple columns and then summarize, it’s important to remember that the summarize “peels off” one of the groups, but leaves the rest on. For example, if you group_by(X, Y) then summarize, the result will still be grouped by X. Calculate the average income (as average_income) of counties within each region and state (notice the group_by() has already been done for you).
Find the state with the lowest average_income in each region.
# Save new data set
counties_selected8 <- counties %>%
select(region, state, county, population, income)
counties_selected8 %>%
group_by(region, state) %>%
# Calculate average income
summarize(average_income = mean(income)) %>%
# Find the lowest income state in each region
slice_min(average_income, n=1)## `summarise()` has grouped output by 'region'. You can override using the
## `.groups` argument.## # A tibble: 4 × 3
## # Groups: region [4]
## region state average_income
## <chr> <chr> <dbl>
## 1 North Central Missouri 41755.
## 2 Northeast Maine 46142.
## 3 South Mississippi 34939.
## 4 West New Mexico 40184.5.2.4 Using summarize, slice_max, and count together
In this chapter, you’ve learned to use six dplyr verbs related to aggregation: count(), group_by(), summarize(), ungroup(), slice_max(), and slice_min(). In this exercise, you’ll combine them to answer a question:
In how many states do more people live in metro areas than non-metro areas?
Recall that the metro column has one of the two values "Metro" (for high-density city areas) or "Nonmetro" (for suburban and country areas).
For each combination of state and metro, find the total population as total_pop.
#Save new data set
counties_selected9 <- counties %>%
select(state, metro, population)
counties_selected9 %>%
# Find the total population for each combination of state and metro
group_by(state, metro) %>%
summarize(total_pop = sum(population))## `summarise()` has grouped output by 'state'. You can override using the
## `.groups` argument.## # A tibble: 97 × 3
## # Groups: state [50]
## state metro total_pop
## <chr> <chr> <dbl>
## 1 Alabama Metro 3671377
## 2 Alabama Nonmetro 1159243
## 3 Alaska Metro 494990
## 4 Alaska Nonmetro 230471
## 5 Arizona Metro 6295145
## 6 Arizona Nonmetro 346783
## 7 Arkansas Metro 1806867
## 8 Arkansas Nonmetro 1151341
## 9 California Metro 37587429
## 10 California Nonmetro 834035
## # ℹ 87 more rowsExtract the most populated row from each state, which will be either Metro or Nonmetro.
counties_selected9 %>%
# Find the total population for each combination of state and metro
group_by(state, metro) %>%
summarize(total_pop = sum(population)) %>%
# Extract the most populated row for each state
slice_max(total_pop, n=1)## `summarise()` has grouped output by 'state'. You can override using the
## `.groups` argument.## # A tibble: 50 × 3
## # Groups: state [50]
## state metro total_pop
## <chr> <chr> <dbl>
## 1 Alabama Metro 3671377
## 2 Alaska Metro 494990
## 3 Arizona Metro 6295145
## 4 Arkansas Metro 1806867
## 5 California Metro 37587429
## 6 Colorado Metro 4590896
## 7 Connecticut Metro 3406918
## 8 Delaware Metro 926454
## 9 Florida Metro 18941821
## 10 Georgia Metro 8233886
## # ℹ 40 more rowsUngroup, then count how often Metro or Nonmetro appears to see how many states have more people living in those areas.
counties_selected9 %>%
# Find the total population for each combination of state and metro
group_by(state, metro) %>%
summarize(total_pop = sum(population)) %>%
# Extract the most populated row for each state
slice_max(total_pop, n = 1) %>%
# Count the states with more people in Metro or Nonmetro areas
ungroup() %>%
count(metro)## `summarise()` has grouped output by 'state'. You can override using the
## `.groups` argument.## # A tibble: 2 × 2
## metro n
## <chr> <int>
## 1 Metro 44
## 2 Nonmetro 65.3 Selecting and Transforming Data
We’ve already seen that we can select the columns that we’re interested in by listing them inside the select verb. This chapter focuses on advanced methods of selecting and transforming columns. There are a ton of variables in the counties dataset, and we often only want to work with a subset of them.
5.3.1 Selecting
We can also select a range of columns. For example, there are a series of columns containing information on how people get to work. If we wanted to select this range of columns from drive to work_at_home, we can use drive colon work_at_home.
5.3.1.1 Selecting columns
Using the select() verb, we can answer interesting questions about our dataset by focusing in on related groups of verbs. The colon (:) is useful for getting many columns at a time.
Use glimpse() to examine all the variables in the counties table.
Select the columns for state, county, population, and (using a colon) all five of those industry-related variables; there are five consecutive variables in the table related to the industry of people’s work: professional, service, office, construction, and production.
Arrange the table in descending order of service to find which counties have the highest rates of working in the service industry.
## Rows: 3,138
## Columns: 40
## $ census_id <chr> "1001", "1003", "1005", "1007", "1009", "1011", "10…
## $ state <chr> "Alabama", "Alabama", "Alabama", "Alabama", "Alabam…
## $ county <chr> "Autauga", "Baldwin", "Barbour", "Bibb", "Blount", …
## $ region <chr> "South", "South", "South", "South", "South", "South…
## $ metro <chr> "Metro", "Metro", "Nonmetro", "Metro", "Metro", "No…
## $ population <dbl> 55221, 195121, 26932, 22604, 57710, 10678, 20354, 1…
## $ men <dbl> 26745, 95314, 14497, 12073, 28512, 5660, 9502, 5627…
## $ women <dbl> 28476, 99807, 12435, 10531, 29198, 5018, 10852, 603…
## $ hispanic <dbl> 2.6, 4.5, 4.6, 2.2, 8.6, 4.4, 1.2, 3.5, 0.4, 1.5, 7…
## $ white <dbl> 75.8, 83.1, 46.2, 74.5, 87.9, 22.2, 53.3, 73.0, 57.…
## $ black <dbl> 18.5, 9.5, 46.7, 21.4, 1.5, 70.7, 43.8, 20.3, 40.3,…
## $ native <dbl> 0.4, 0.6, 0.2, 0.4, 0.3, 1.2, 0.1, 0.2, 0.2, 0.6, 0…
## $ asian <dbl> 1.0, 0.7, 0.4, 0.1, 0.1, 0.2, 0.4, 0.9, 0.8, 0.3, 0…
## $ pacific <dbl> 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0…
## $ citizens <dbl> 40725, 147695, 20714, 17495, 42345, 8057, 15581, 88…
## $ income <dbl> 51281, 50254, 32964, 38678, 45813, 31938, 32229, 41…
## $ income_err <dbl> 2391, 1263, 2973, 3995, 3141, 5884, 1793, 925, 2949…
## $ income_per_cap <dbl> 24974, 27317, 16824, 18431, 20532, 17580, 18390, 21…
## $ income_per_cap_err <dbl> 1080, 711, 798, 1618, 708, 2055, 714, 489, 1366, 15…
## $ poverty <dbl> 12.9, 13.4, 26.7, 16.8, 16.7, 24.6, 25.4, 20.5, 21.…
## $ child_poverty <dbl> 18.6, 19.2, 45.3, 27.9, 27.2, 38.4, 39.2, 31.6, 37.…
## $ professional <dbl> 33.2, 33.1, 26.8, 21.5, 28.5, 18.8, 27.5, 27.3, 23.…
## $ service <dbl> 17.0, 17.7, 16.1, 17.9, 14.1, 15.0, 16.6, 17.7, 14.…
## $ office <dbl> 24.2, 27.1, 23.1, 17.8, 23.9, 19.7, 21.9, 24.2, 26.…
## $ construction <dbl> 8.6, 10.8, 10.8, 19.0, 13.5, 20.1, 10.3, 10.5, 11.5…
## $ production <dbl> 17.1, 11.2, 23.1, 23.7, 19.9, 26.4, 23.7, 20.4, 24.…
## $ drive <dbl> 87.5, 84.7, 83.8, 83.2, 84.9, 74.9, 84.5, 85.3, 85.…
## $ carpool <dbl> 8.8, 8.8, 10.9, 13.5, 11.2, 14.9, 12.4, 9.4, 11.9, …
## $ transit <dbl> 0.1, 0.1, 0.4, 0.5, 0.4, 0.7, 0.0, 0.2, 0.2, 0.2, 0…
## $ walk <dbl> 0.5, 1.0, 1.8, 0.6, 0.9, 5.0, 0.8, 1.2, 0.3, 0.6, 1…
## $ other_transp <dbl> 1.3, 1.4, 1.5, 1.5, 0.4, 1.7, 0.6, 1.2, 0.4, 0.7, 1…
## $ work_at_home <dbl> 1.8, 3.9, 1.6, 0.7, 2.3, 2.8, 1.7, 2.7, 2.1, 2.5, 1…
## $ mean_commute <dbl> 26.5, 26.4, 24.1, 28.8, 34.9, 27.5, 24.6, 24.1, 25.…
## $ employed <dbl> 23986, 85953, 8597, 8294, 22189, 3865, 7813, 47401,…
## $ private_work <dbl> 73.6, 81.5, 71.8, 76.8, 82.0, 79.5, 77.4, 74.1, 85.…
## $ public_work <dbl> 20.9, 12.3, 20.8, 16.1, 13.5, 15.1, 16.2, 20.8, 12.…
## $ self_employed <dbl> 5.5, 5.8, 7.3, 6.7, 4.2, 5.4, 6.2, 5.0, 2.8, 7.9, 4…
## $ family_work <dbl> 0.0, 0.4, 0.1, 0.4, 0.4, 0.0, 0.2, 0.1, 0.0, 0.5, 0…
## $ unemployment <dbl> 7.6, 7.5, 17.6, 8.3, 7.7, 18.0, 10.9, 12.3, 8.9, 7.…
## $ land_area <dbl> 594.44, 1589.78, 884.88, 622.58, 644.78, 622.81, 77…counties %>%
# Select state, county, population, and industry-related columns
select(state, county, population, professional:production) %>%
# Arrange service in descending order
arrange(desc(service))## # A tibble: 3,138 × 8
## state county population professional service office construction production
## <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 Missis… Tunica 10477 23.9 36.6 21.5 3.5 14.5
## 2 Texas Kinney 3577 30 36.5 11.6 20.5 1.3
## 3 Texas Kenedy 565 24.9 34.1 20.5 20.5 0
## 4 New Yo… Bronx 1428357 24.3 33.3 24.2 7.1 11
## 5 Texas Brooks 7221 19.6 32.4 25.3 11.1 11.5
## 6 Colora… Fremo… 46809 26.6 32.2 22.8 10.7 7.6
## 7 Texas Culbe… 2296 20.1 32.2 24.2 15.7 7.8
## 8 Califo… Del N… 27788 33.9 31.5 18.8 8.9 6.8
## 9 Minnes… Mahno… 5496 26.8 31.5 18.7 13.1 9.9
## 10 Virgin… Lanca… 11129 30.3 31.2 22.8 8.1 7.6
## # ℹ 3,128 more rows5.3.1.2 Select helpers
In the video you learned about the select helper starts_with(). Another select helper is ends_with(), which finds the columns that end with a particular string.
Select the columns state, county, population, and all those that end with work.
Filter just for the counties where at least 50% of the population is engaged in public work.
counties %>%
# Select the state, county, population, and those ending with "work"
select(state, county, population, ends_with("work")) %>%
# Filter for counties that have at least 50% of people engaged in public work
filter(public_work > 50)## # A tibble: 7 × 6
## state county population private_work public_work family_work
## <chr> <chr> <dbl> <dbl> <dbl> <dbl>
## 1 Alaska Lake and Peninsu… 1474 42.2 51.6 0.2
## 2 Alaska Yukon-Koyukuk Ce… 5644 33.3 61.7 0
## 3 California Lassen 32645 42.6 50.5 0.1
## 4 Hawaii Kalawao 85 25 64.1 0
## 5 North Dakota Sioux 4380 32.9 56.8 0.1
## 6 South Dakota Todd 9942 34.4 55 0.8
## 7 Wisconsin Menominee 4451 36.8 59.1 0.45.3.2 The rename verb
Often, rather than only selecting columns, we’ll sometimes want to rename the ones we already have. We’ll learn a new verb to do this: the rename() verb.
5.3.2.1 Renaming a column after count
The rename() verb is often useful for changing the name of a column that comes out of another verb, such as count(). In this exercise, you’ll rename the default n column generated from count() to something more descriptive.
Use count() to determine how many counties are in each state.
## # A tibble: 50 × 2
## state n
## <chr> <int>
## 1 Alabama 67
## 2 Alaska 28
## 3 Arizona 15
## 4 Arkansas 75
## 5 California 58
## 6 Colorado 64
## 7 Connecticut 8
## 8 Delaware 3
## 9 Florida 67
## 10 Georgia 159
## # ℹ 40 more rowsNotice the n column in the output; use rename() to rename that to num_counties.
counties %>%
# Count the number of counties in each state
count(state) %>%
# Rename the n column to num_counties
rename(num_counties=n)## # A tibble: 50 × 2
## state num_counties
## <chr> <int>
## 1 Alabama 67
## 2 Alaska 28
## 3 Arizona 15
## 4 Arkansas 75
## 5 California 58
## 6 Colorado 64
## 7 Connecticut 8
## 8 Delaware 3
## 9 Florida 67
## 10 Georgia 159
## # ℹ 40 more rows5.3.2.2 Renaming a column as part of a select
rename() isn’t the only way you can choose a new name for a column; you can also choose a name as part of a select().
Select the columns state, county, and poverty from the counties dataset; in the same step, rename the poverty column to poverty_rate.
counties %>%
# Select state, county, and poverty as poverty_rate
select(state, county, poverty_rate = poverty)## # A tibble: 3,138 × 3
## state county poverty_rate
## <chr> <chr> <dbl>
## 1 Alabama Autauga 12.9
## 2 Alabama Baldwin 13.4
## 3 Alabama Barbour 26.7
## 4 Alabama Bibb 16.8
## 5 Alabama Blount 16.7
## 6 Alabama Bullock 24.6
## 7 Alabama Butler 25.4
## 8 Alabama Calhoun 20.5
## 9 Alabama Chambers 21.6
## 10 Alabama Cherokee 19.2
## # ℹ 3,128 more rows5.3.3 The relocate verb
We’ve learned about the select, rename, and mutate verbs for transforming data, but now we’ll learn a fourth one: relocate().
5.3.3.1 Using relocate
As you learned in the video, the relocate() verb allows you to move columns around relative to other columns or its overall position in the tibble.
You’ve been given the counties_selected tibble, which contains the columns you need for your analysis of population density, but in an order that isn’t easy to read. You’ll use your new-found skills to put them right!
Move the density column to the end of the tibble.
Move the population column to before the land_area column.
counties_selected10 <- counties %>%
select(population, land_area) %>%
mutate(density = population / land_area)
counties_selected10 %>%
# Move the density column to the end
relocate(density, .after = last_col()) %>%
# Move the population column to before land_area
relocate(population, .before = land_area)## # A tibble: 3,138 × 3
## population land_area density
## <dbl> <dbl> <dbl>
## 1 55221 594. 92.9
## 2 195121 1590. 123.
## 3 26932 885. 30.4
## 4 22604 623. 36.3
## 5 57710 645. 89.5
## 6 10678 623. 17.1
## 7 20354 777. 26.2
## 8 116648 606. 193.
## 9 34079 597. 57.1
## 10 26008 554. 47.0
## # ℹ 3,128 more rows5.3.3.2 Choosing among the four verbs
In this chapter you’ve learned about the four verbs: select(), mutate(), relocate(), and rename(). Here, you’ll choose the appropriate verb for each situation. You won’t need to change anything inside the parentheses.
Choose the right verb for changing the name of the ‘unemployment’ column to ‘unemployment_rate’ Choose the right verb for keeping only the columns ‘state’, ‘county’, and the ones containing ‘poverty.’ Calculate a new column called ‘fraction_women’ with the fraction of the population made up of women, without dropping any columns. Keep only three columns: the ‘state’, ‘county’, and ‘employed’ / ‘population’, which you’ll call ‘employment_rate.’
## # A tibble: 3,138 × 40
## census_id state county region metro population men women hispanic white
## <chr> <chr> <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 1001 Alabama Autauga South Metro 55221 26745 28476 2.6 75.8
## 2 1003 Alabama Baldwin South Metro 195121 95314 99807 4.5 83.1
## 3 1005 Alabama Barbour South Nonm… 26932 14497 12435 4.6 46.2
## 4 1007 Alabama Bibb South Metro 22604 12073 10531 2.2 74.5
## 5 1009 Alabama Blount South Metro 57710 28512 29198 8.6 87.9
## 6 1011 Alabama Bullock South Nonm… 10678 5660 5018 4.4 22.2
## 7 1013 Alabama Butler South Nonm… 20354 9502 10852 1.2 53.3
## 8 1015 Alabama Calhoun South Metro 116648 56274 60374 3.5 73
## 9 1017 Alabama Chambers South Nonm… 34079 16258 17821 0.4 57.3
## 10 1019 Alabama Cherokee South Nonm… 26008 12975 13033 1.5 91.7
## # ℹ 3,128 more rows
## # ℹ 30 more variables: black <dbl>, native <dbl>, asian <dbl>, pacific <dbl>,
## # citizens <dbl>, income <dbl>, income_err <dbl>, income_per_cap <dbl>,
## # income_per_cap_err <dbl>, poverty <dbl>, child_poverty <dbl>,
## # professional <dbl>, service <dbl>, office <dbl>, construction <dbl>,
## # production <dbl>, drive <dbl>, carpool <dbl>, transit <dbl>, walk <dbl>,
## # other_transp <dbl>, work_at_home <dbl>, mean_commute <dbl>, …# Keep the state and county columns, and the columns containing poverty
counties %>%
select(state, county, contains("poverty"))## # A tibble: 3,138 × 4
## state county poverty child_poverty
## <chr> <chr> <dbl> <dbl>
## 1 Alabama Autauga 12.9 18.6
## 2 Alabama Baldwin 13.4 19.2
## 3 Alabama Barbour 26.7 45.3
## 4 Alabama Bibb 16.8 27.9
## 5 Alabama Blount 16.7 27.2
## 6 Alabama Bullock 24.6 38.4
## 7 Alabama Butler 25.4 39.2
## 8 Alabama Calhoun 20.5 31.6
## 9 Alabama Chambers 21.6 37.2
## 10 Alabama Cherokee 19.2 30.1
## # ℹ 3,128 more rows# Calculate the fraction_women column without dropping the other columns
counties %>%
mutate(fraction_women = women / population)## # A tibble: 3,138 × 41
## census_id state county region metro population men women hispanic white
## <chr> <chr> <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 1001 Alabama Autauga South Metro 55221 26745 28476 2.6 75.8
## 2 1003 Alabama Baldwin South Metro 195121 95314 99807 4.5 83.1
## 3 1005 Alabama Barbour South Nonm… 26932 14497 12435 4.6 46.2
## 4 1007 Alabama Bibb South Metro 22604 12073 10531 2.2 74.5
## 5 1009 Alabama Blount South Metro 57710 28512 29198 8.6 87.9
## 6 1011 Alabama Bullock South Nonm… 10678 5660 5018 4.4 22.2
## 7 1013 Alabama Butler South Nonm… 20354 9502 10852 1.2 53.3
## 8 1015 Alabama Calhoun South Metro 116648 56274 60374 3.5 73
## 9 1017 Alabama Chambers South Nonm… 34079 16258 17821 0.4 57.3
## 10 1019 Alabama Cherokee South Nonm… 26008 12975 13033 1.5 91.7
## # ℹ 3,128 more rows
## # ℹ 31 more variables: black <dbl>, native <dbl>, asian <dbl>, pacific <dbl>,
## # citizens <dbl>, income <dbl>, income_err <dbl>, income_per_cap <dbl>,
## # income_per_cap_err <dbl>, poverty <dbl>, child_poverty <dbl>,
## # professional <dbl>, service <dbl>, office <dbl>, construction <dbl>,
## # production <dbl>, drive <dbl>, carpool <dbl>, transit <dbl>, walk <dbl>,
## # other_transp <dbl>, work_at_home <dbl>, mean_commute <dbl>, …## # A tibble: 3,138 × 40
## census_id region state county metro population men women hispanic white
## <chr> <chr> <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 1001 South Alabama Autauga Metro 55221 26745 28476 2.6 75.8
## 2 1003 South Alabama Baldwin Metro 195121 95314 99807 4.5 83.1
## 3 1005 South Alabama Barbour Nonm… 26932 14497 12435 4.6 46.2
## 4 1007 South Alabama Bibb Metro 22604 12073 10531 2.2 74.5
## 5 1009 South Alabama Blount Metro 57710 28512 29198 8.6 87.9
## 6 1011 South Alabama Bullock Nonm… 10678 5660 5018 4.4 22.2
## 7 1013 South Alabama Butler Nonm… 20354 9502 10852 1.2 53.3
## 8 1015 South Alabama Calhoun Metro 116648 56274 60374 3.5 73
## 9 1017 South Alabama Chambers Nonm… 34079 16258 17821 0.4 57.3
## 10 1019 South Alabama Cherokee Nonm… 26008 12975 13033 1.5 91.7
## # ℹ 3,128 more rows
## # ℹ 30 more variables: black <dbl>, native <dbl>, asian <dbl>, pacific <dbl>,
## # citizens <dbl>, income <dbl>, income_err <dbl>, income_per_cap <dbl>,
## # income_per_cap_err <dbl>, poverty <dbl>, child_poverty <dbl>,
## # professional <dbl>, service <dbl>, office <dbl>, construction <dbl>,
## # production <dbl>, drive <dbl>, carpool <dbl>, transit <dbl>, walk <dbl>,
## # other_transp <dbl>, work_at_home <dbl>, mean_commute <dbl>, …5.4 Case Study: The babynames Dataset
So far in this course, we’ve been using the counties dataset, which contains US census data at a county level. In this chapter, we’re going to analyze a new dataset, one representing the names of babies born in the United States each year.
5.4.1 Filtering and arranging for one year
The dplyr verbs you’ve learned are useful for exploring data. For instance, you could find out the most common names in a particular year.
Filter for only the year 1990. Sort the table in descending order of the number of babies born.
babynames %>%
# Filter for the year 1990
filter(year == 1990) %>%
# Sort the number column in descending order
arrange(desc(number))## # A tibble: 21,223 × 3
## year name number
## <dbl> <chr> <int>
## 1 1990 Michael 65560
## 2 1990 Christopher 52520
## 3 1990 Jessica 46615
## 4 1990 Ashley 45797
## 5 1990 Matthew 44925
## 6 1990 Joshua 43382
## 7 1990 Brittany 36650
## 8 1990 Amanda 34504
## 9 1990 Daniel 33963
## 10 1990 David 33862
## # ℹ 21,213 more rows5.4.2 Finding the most popular names each year
You saw that you could use filter() and arrange() to find the most common names in one year. However, you could also use group_by() and slice_max() to find the most common name in every year.
Use group_by() and slice_max() to find the most common name for US babies in each year.
## # A tibble: 28 × 3
## # Groups: year [28]
## year name number
## <dbl> <chr> <int>
## 1 1880 John 9701
## 2 1885 Mary 9166
## 3 1890 Mary 12113
## 4 1895 Mary 13493
## 5 1900 Mary 16781
## 6 1905 Mary 16135
## 7 1910 Mary 22947
## 8 1915 Mary 58346
## 9 1920 Mary 71175
## 10 1925 Mary 70857
## # ℹ 18 more rows5.4.3 Visualizing names with ggplot2
The dplyr package is very useful for exploring data, but it’s especially useful when combined with other tidyverse packages like ggplot2.
Filter for only the names Steven, Thomas, and Matthew, and assign it to an object called selected_names. Hint: set up a vector to contain the names using %in%
selected_names <- babynames %>%
# Filter for the names Steven, Thomas, and Matthew
filter(name %in% c("Steven", "Thomas", "Matthew"))Visualize those three names as a line plot over time, with each name represented by a different color.
# Plot the names using a different color for each name
ggplot(selected_names, aes(x = year, y = number, color = name)) +
geom_line()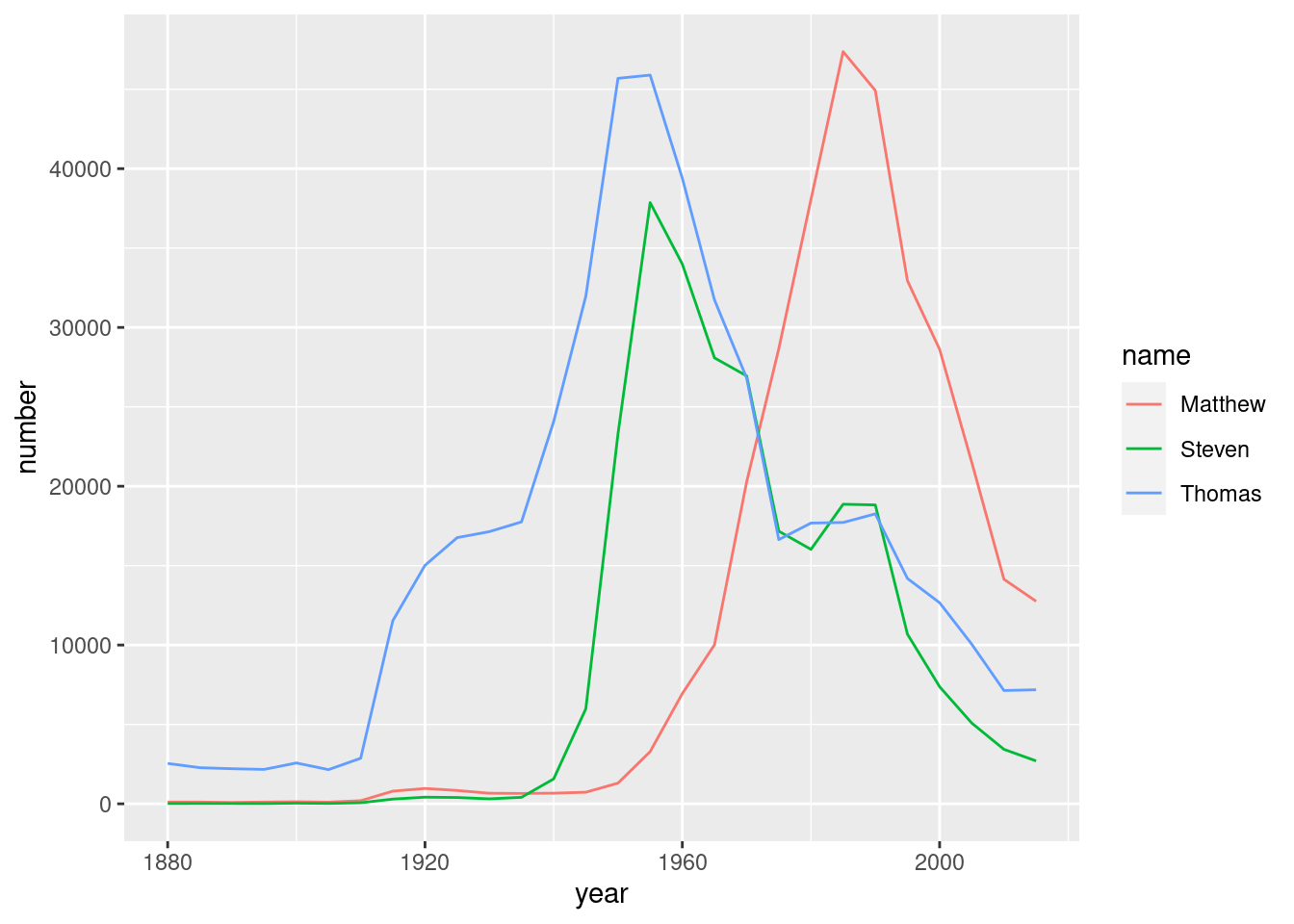
5.4.4 Grouped mutates
Just like group_by and summarize work well together, group_by and mutate are a great pair.
5.4.4.1 Finding the year each name is most common
In an earlier video, you learned how to filter for a particular name to determine the frequency of that name over time. Now, you’re going to explore which year each name was the most common.
To do this, you’ll be combining the grouped mutate approach with a slice_max().
First, calculate the total number of people born in that year in this dataset as year_total.
Next, use year_total to calculate the fraction of people born in each year that have each name.
# Calculate the fraction of people born each year with the same name
babynames %>%
group_by(year) %>%
mutate(year_total = sum(number)) %>%
ungroup() %>%
mutate(fraction = number / year_total)## # A tibble: 332,595 × 5
## year name number year_total fraction
## <dbl> <chr> <int> <int> <dbl>
## 1 1880 Aaron 102 201478 0.000506
## 2 1880 Ab 5 201478 0.0000248
## 3 1880 Abbie 71 201478 0.000352
## 4 1880 Abbott 5 201478 0.0000248
## 5 1880 Abby 6 201478 0.0000298
## 6 1880 Abe 50 201478 0.000248
## 7 1880 Abel 9 201478 0.0000447
## 8 1880 Abigail 12 201478 0.0000596
## 9 1880 Abner 27 201478 0.000134
## 10 1880 Abraham 81 201478 0.000402
## # ℹ 332,585 more rowsNow use your newly calculated fraction column, in combination with slice_max(), to identify the year each name was most common.
# Calculate the fraction of people born each year with the same name
babynames %>%
group_by(year) %>%
mutate(year_total = sum(number)) %>%
ungroup() %>%
mutate(fraction = number / year_total) %>%
# Find the year each name is most common
group_by(name) %>%
slice_max(fraction, n = 1)## # A tibble: 48,040 × 5
## # Groups: name [48,040]
## year name number year_total fraction
## <dbl> <chr> <int> <int> <dbl>
## 1 2015 Aaban 15 3648781 0.00000411
## 2 2015 Aadam 22 3648781 0.00000603
## 3 2010 Aadan 11 3672066 0.00000300
## 4 2015 Aadarsh 15 3648781 0.00000411
## 5 2010 Aaden 450 3672066 0.000123
## 6 2015 Aadhav 31 3648781 0.00000850
## 7 2015 Aadhavan 5 3648781 0.00000137
## 8 2015 Aadhya 265 3648781 0.0000726
## 9 2010 Aadi 54 3672066 0.0000147
## 10 2005 Aadil 20 3828460 0.00000522
## # ℹ 48,030 more rows5.4.4.2 Adding the total and maximum for each name
In the video, you learned how you could group by the year and use mutate() to add a total for that year.
In these exercises, you’ll learn to normalize by a different, but also interesting metric: you’ll divide each name by the maximum for that name. This means that every name will peak at 1.
Once you add new columns, the result will still be grouped by name. This splits it into 48,000 groups, which actually makes later steps like mutates slower.
Use a grouped mutate to add two columns: name_total: the sum of the number of babies born with that name in the entire dataset. name_max: the maximum number of babies born with that name in any year.
babynames %>%
# Add columns name_total and name_max for each name
group_by(name) %>%
mutate(name_total = sum(number),
name_max = max(number))## # A tibble: 332,595 × 5
## # Groups: name [48,040]
## year name number name_total name_max
## <dbl> <chr> <int> <int> <int>
## 1 1880 Aaron 102 114739 14635
## 2 1880 Ab 5 77 31
## 3 1880 Abbie 71 4330 445
## 4 1880 Abbott 5 217 51
## 5 1880 Abby 6 11272 1753
## 6 1880 Abe 50 1832 271
## 7 1880 Abel 9 10565 3245
## 8 1880 Abigail 12 72600 15762
## 9 1880 Abner 27 1552 199
## 10 1880 Abraham 81 17882 2449
## # ℹ 332,585 more rowsAdd another step to ungroup the table. Add a column called fraction_max containing the number in the year divided by name_max.
babynames %>%
# Add columns name_total and name_max for each name
group_by(name) %>%
mutate(name_total = sum(number),
name_max = max(number)) %>%
# Ungroup the table
ungroup() %>%
# Add the fraction_max column containing the number by the name maximum
mutate(fraction_max = number / name_max)## # A tibble: 332,595 × 6
## year name number name_total name_max fraction_max
## <dbl> <chr> <int> <int> <int> <dbl>
## 1 1880 Aaron 102 114739 14635 0.00697
## 2 1880 Ab 5 77 31 0.161
## 3 1880 Abbie 71 4330 445 0.160
## 4 1880 Abbott 5 217 51 0.0980
## 5 1880 Abby 6 11272 1753 0.00342
## 6 1880 Abe 50 1832 271 0.185
## 7 1880 Abel 9 10565 3245 0.00277
## 8 1880 Abigail 12 72600 15762 0.000761
## 9 1880 Abner 27 1552 199 0.136
## 10 1880 Abraham 81 17882 2449 0.0331
## # ℹ 332,585 more rows5.4.4.3 Visualizing the normalized change in popularity
You picked a few names and calculated each of them as a fraction of their peak. This is a type of “normalizing” a name, where you’re focused on the relative change within each name rather than the overall popularity of the name.
Filter the names_normalized table to limit it to the three names Steven, Thomas, and Matthew.
Create a line plot from names_filtered to visualize fraction_max over time, colored by name.
# Table provided in datacamp
names_normalized <- babynames %>%
group_by(name) %>%
mutate(name_total = sum(number),
name_max = max(number)) %>%
ungroup() %>%
mutate(fraction_max = number / name_max)
names_filtered <- names_normalized %>%
# Filter for the names Steven, Thomas, and Matthew
filter(name %in% c("Steven", "Thomas", "Matthew"))
# Visualize the names in names_filtered over time
ggplot(data = names_filtered, aes(x=year, y=fraction_max, color = name)) +
geom_line()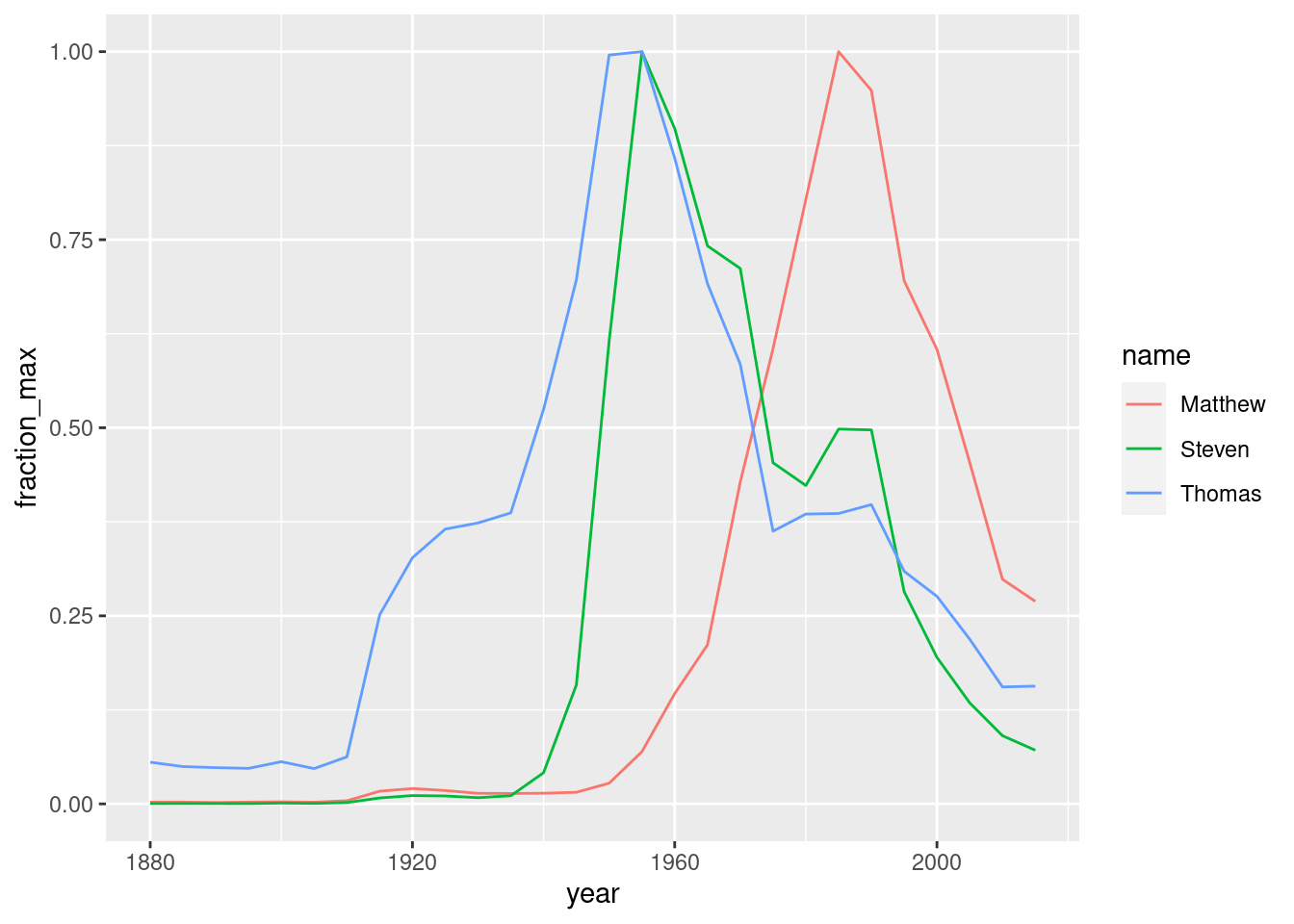
5.4.5 Window functions
A window function takes a vector, and returns another vector of the same length.
5.4.5.1 Using ratios to describe the frequency of a name
In the video, you learned how to find the difference in the frequency of a baby name between consecutive years. What if instead of finding the difference, you wanted to find the ratio?
You’ll start with the babynames_fraction data already, so that you can consider the popularity of each name within each year.
Arrange the data in ascending order of name and then year.
Group by name so that your mutate works within each name.
Add a column ratio containing the ratio (not difference) of fraction between each year.
Hint: when creating a new variable with the lag function, he format is variable _ lag(variable) the _ will be different depending on if you are calculation a ratio or a difference
# Data set given in data camp
babynames_fraction <- babynames %>%
group_by(year) %>%
mutate(year_total = sum(number)) %>%
ungroup() %>%
mutate(fraction = number / year_total)
babynames_fraction %>%
# Arrange the data in order of name, then year
arrange(name, year) %>%
# Group the data by name
group_by(name) %>%
# Add a ratio column that contains the ratio of fraction between each year
mutate(ratio = fraction / lag(fraction))## # A tibble: 332,595 × 6
## # Groups: name [48,040]
## year name number year_total fraction ratio
## <dbl> <chr> <int> <int> <dbl> <dbl>
## 1 2010 Aaban 9 3672066 0.00000245 NA
## 2 2015 Aaban 15 3648781 0.00000411 1.68
## 3 1995 Aadam 6 3652750 0.00000164 NA
## 4 2000 Aadam 6 3767293 0.00000159 0.970
## 5 2005 Aadam 6 3828460 0.00000157 0.984
## 6 2010 Aadam 7 3672066 0.00000191 1.22
## 7 2015 Aadam 22 3648781 0.00000603 3.16
## 8 2010 Aadan 11 3672066 0.00000300 NA
## 9 2015 Aadan 10 3648781 0.00000274 0.915
## 10 2000 Aadarsh 5 3767293 0.00000133 NA
## # ℹ 332,585 more rows5.4.5.2 Biggest jumps in a name
Previously, you added a ratio column to describe the ratio of the frequency of a baby name between consecutive years to describe the changes in the popularity of a name. Now, you’ll look at a subset of that data, called babynames_ratios_filtered, to look further into the names that experienced the biggest jumps in popularity in consecutive years.
From each name in the data, keep the observation (the year) with the largest ratio; note the data is already grouped by name.
Sort the ratio column in descending order.
Filter the babynames_ratios_filtered data further by filtering the fraction column to only display results greater than or equal to 0.001.
# Dataset given in datacamp
babynames_ratios_filtered <- babynames_fraction %>%
arrange(name, year) %>%
group_by(name) %>%
mutate(ratio = fraction / lag(fraction)) %>%
filter(fraction >= 0.00001)
babynames_ratios_filtered %>%
# Extract the largest ratio from each name
slice_max(ratio, n=1) %>%
# Sort the ratio column in descending order
arrange(desc(ratio)) %>%
# Filter for fractions greater than or equal to 0.001
filter(fraction >= 0.001)## # A tibble: 291 × 6
## # Groups: name [291]
## year name number year_total fraction ratio
## <dbl> <chr> <int> <int> <dbl> <dbl>
## 1 1960 Tammy 14365 4152075 0.00346 70.1
## 2 2005 Nevaeh 4610 3828460 0.00120 45.8
## 3 1940 Brenda 5460 2301630 0.00237 37.5
## 4 1885 Grover 774 240822 0.00321 36.0
## 5 1945 Cheryl 8170 2652029 0.00308 24.9
## 6 1955 Lori 4980 4012691 0.00124 23.2
## 7 2010 Khloe 5411 3672066 0.00147 23.2
## 8 1950 Debra 6189 3502592 0.00177 22.6
## 9 2010 Bentley 4001 3672066 0.00109 22.4
## 10 1935 Marlene 4840 2088487 0.00232 16.8
## # ℹ 281 more rows