12 Dummy Variables Part 1
This chapter serves as a bridge between working with continuous explanatory variables and binary explanatory variables, often called indicator variables or dummy variables. A dummy variable is a variable that can have only two values, 0 and 1. A value of 1 indicates that the condition is true, while a value of 0 indicates that the condition is false. The “condition” indicated by the variable can be based on qualitative information (e.g., being a particular race, ethnicity, gender, or nationality), quantitative information (e.g., being over the age of 65, living in a house with more than 5 people), or some mix of the two (e.g., having a particular degree instead of years of education). As an example, if we have data on individuals from different US States, we might have a dummy variable WI, where WI=1 indicates the person is from Wisconsin and WI=0 indicates they are NOT from Wisconsin. It is always important to understand the data to understand what the “NOT” condition means. For example, if the data includes people from Illinois and Wisconsin, WI=0 indicates the person is from Illinois. If the data contains people from all 50 states, than WI=0 indicates they are from any state other than Wisconsin.
This chapter uses the data in HousePriceDummies.csv with price of the house in dollars (price), size of the hose in square feet (size), number of bathrooms (baths), and number of bedrooms (beds). This chapter serves as a bridge between working with continuous explanatory variables and dummy variables because you will construct a dummy variable from a variable you have previously used as a continuous variable (the number of bathrooms).
From this chapter you will learn about intercept dummies that allow the average \(y\) value to differ by group by the same amount for all values of the other explanatory variables (this should sound familiar from week 1 with houses that have a garage). Intercept dummies are the most common use of dummy variables. You’ll create an intercept dummy from a numerical variable (baths) that only has two possible values, so while you’re working with a dummy variable, you’re actually just working with regression models you should already understand. This hopefully helps you better understand how to work with all dummy variables, including those based on qualitative information, not just quantitative information like the number of bathrooms. You will also learn about slope dummies that allow the slope to vary by group (slope dummies are actually just a dummy variable multiplied by a continuous variable).
Wherever you see qCnt() in the RMD file you’ll see a number in the HTML output. qCnt() is a counter (defined in the code chunk above) that is putting what are essentially question numbers in the HTML output. This makes it easier to discuss with others because we can refer to the different questions by number.
As you go through the file, you need to do something (add code, short answers) for each question everywhere it says YOUR ANSWER HERE. This is what I will be checking for when I check off your work. We will start out working on this together in class, although you may need to finish on your own.
Let’s jump in…
12.1 Data
## Load Data
mydata <- read.csv("https://raw.githubusercontent.com/LhostEcon/380data/main/HousePriceDummies.csv")Summary statistics
stargazer(mydata, type = "html",summary.stat = c("mean","sd", "min", "p25", "median", "p75", "max"))| Statistic | Mean | St. Dev. | Min | Pctl(25) | Median | Pctl(75) | Max |
| price | 348,436.100 | 94,150.230 | 109,904 | 285,144 | 347,862 | 408,484.2 | 611,257 |
| size | 1,938.569 | 493.908 | 877 | 1,536.8 | 1,910.5 | 2,323.8 | 2,965 |
| beds | 2.630 | 0.999 | 1 | 2 | 3 | 3 | 4 |
| baths | 1.528 | 0.500 | 1 | 1 | 2 | 2 | 2 |
12.2 Size only
1) In this first code chunk, first estimate the simple linear regression model of price on size and store it in modelS (that’s “model” and a capital letter “S” for “Size”). Then display modelS using pander. Next, add a variable yHatS to the mydatadata frame with the predicted price from modelS. Yes, R has a fitted() function to do this for you, but I want you to calculate it manually using:
\[ \hat{y} = \hat{\beta}_0 + \hat{\beta}_1 size \]
Finally, create a scatter plot of the data using the number of bathrooms (baths) as a factor for the color (we need factor() so it treats baths as distinct integers, 1 and 2, instead of a continuous variable that could have values like 1.234). We also include yHatS as a scatterplot and as a line (also using yHatS). Make sure you understand why all of the yHatS points are on the yHatS line. Throughout this chapter we’ll use an “x” symbol (ggplot’s shape=4) to display the data and dots (i.e., filled-in circles, ggplot’s shape=19, which is also it’s default) to display predicted prices (i.e., yHatS).
I filled this first one in for you (feel free to copy/paste and use this as a basis for what you do).
| Estimate | Std. Error | t value | Pr(>|t|) | |
|---|---|---|---|---|
| (Intercept) | 49174 | 15291 | 3.216 | 0.001502 |
| size | 154.4 | 7.645 | 20.19 | 1.826e-51 |
| Observations | Residual Std. Error | \(R^2\) | Adjusted \(R^2\) |
|---|---|---|---|
| 216 | 55363 | 0.6558 | 0.6542 |
mydata$yHatS <- coef(modelS)["(Intercept)"] + coef(modelS)["size"] * mydata$size
ggplot(mydata) +
geom_point(aes(y=price,x=size,col=factor(baths)),shape=4) +
geom_point(aes(y=yHatS,x=size,col=factor(baths))) +
geom_line(aes(y=yHatS,x=size),col="black")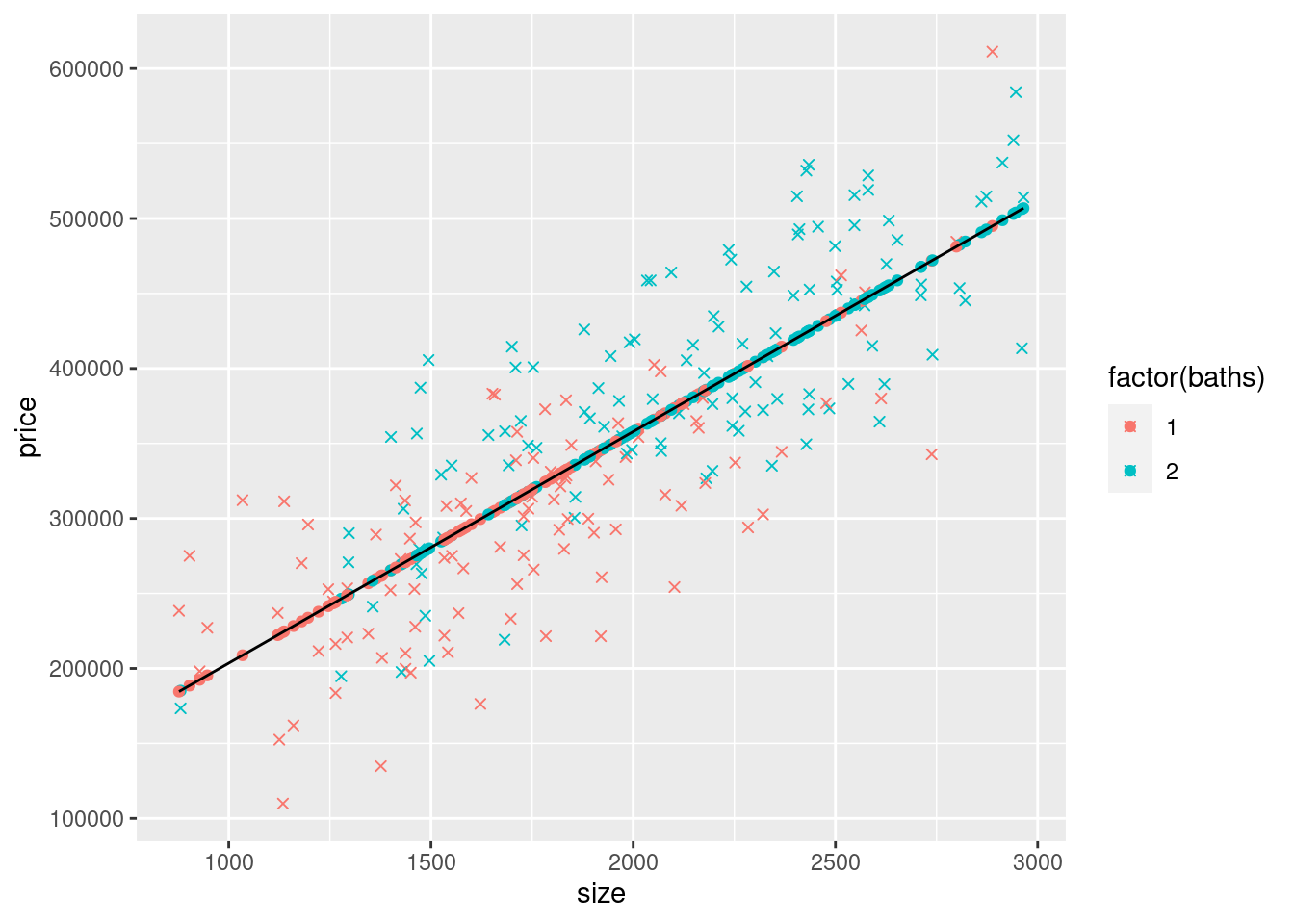
Note how we used coef(modelS)["(Intercept)"] to get the value of the intercept and coef(modelS)["size"] to get the value of the coefficient on size. We do NOT look at the output and type the value. Hard-coding the value (i.e., typing it) leads to errors, both from typos and from not updating values if the data or model change (thus changing the coefficients). Make sure to do this throughout anywhere you need to use the values of regression coefficients.
2) A big part of our focus in this chapter is the regression lines, so let’s be more explicit about plotting the line. The line we plotted above used geom_line(aes(y=yHatS,x=size)). We could plot this same line using geom_smooth, but later we’re going to plot lines that don’t work easily with geom_smooth. Instead, we’re going to use use geom_abline() to plot a line using its intercept and slope. Recall that yHatS is:
\[
\hat{y} = \hat{\beta}_0 + \hat{\beta}_1 size
\]
so we need to use \(\hat{\beta}_0=\) 49173.68 for geom_abline’s intercept argument and \(\hat{\beta}_1=\) 154.37 for geom_abline’s slope argument. Note that when you use coef(modelS)["(Intercept)"] and coef(modelS)["size"] for the intercept and slope arguments of geom_abline, you don’t include the format() function, or it’s arguments (digits=2,nsmall=2), which were just used to display the values in this paragraph in a nicely-formatted way.
We’ll also expand the axes limits so we can see the y intercepts; to do this, we’ll include:
scale_x_continuous(expand = c(0, 0),limits = c(0, max(mydata$size)*1.02),breaks = seq(0,max(mydata$size)*1.02,500))
and
scale_y_continuous(expand = c(0, 0),limits = c(0, max(mydata$price)*1.02), breaks = seq(0,max(mydata$price)*1.02,50000))
YOUR ANSWER HERE (scatterplot of size (x axis) vs price (y axis) with colors by baths as a factor with the SLR regression line added using geom_abline() with the slope and intercept coming directly from coef(modelS))
ggplot(mydata) +
geom_point(aes(y=price,x=size,col=factor(baths)),shape=4) +
geom_point(aes(y=yHatS,x=size,col=factor(baths))) +
geom_line(aes(y=yHatS,x=size),col="black") +
geom_abline(intercept=coef(modelS)["(Intercept)"],slope=coef(modelS)["size"], col = "black") + scale_x_continuous(expand = c(0, 0),limits = c(0, max(mydata$size)*1.02),breaks = seq(0,max(mydata$size)*1.02,500)) +
scale_y_continuous(expand = c(0, 0),limits = c(0, max(mydata$price)*1.02), breaks = seq(0,max(mydata$price)*1.02,50000))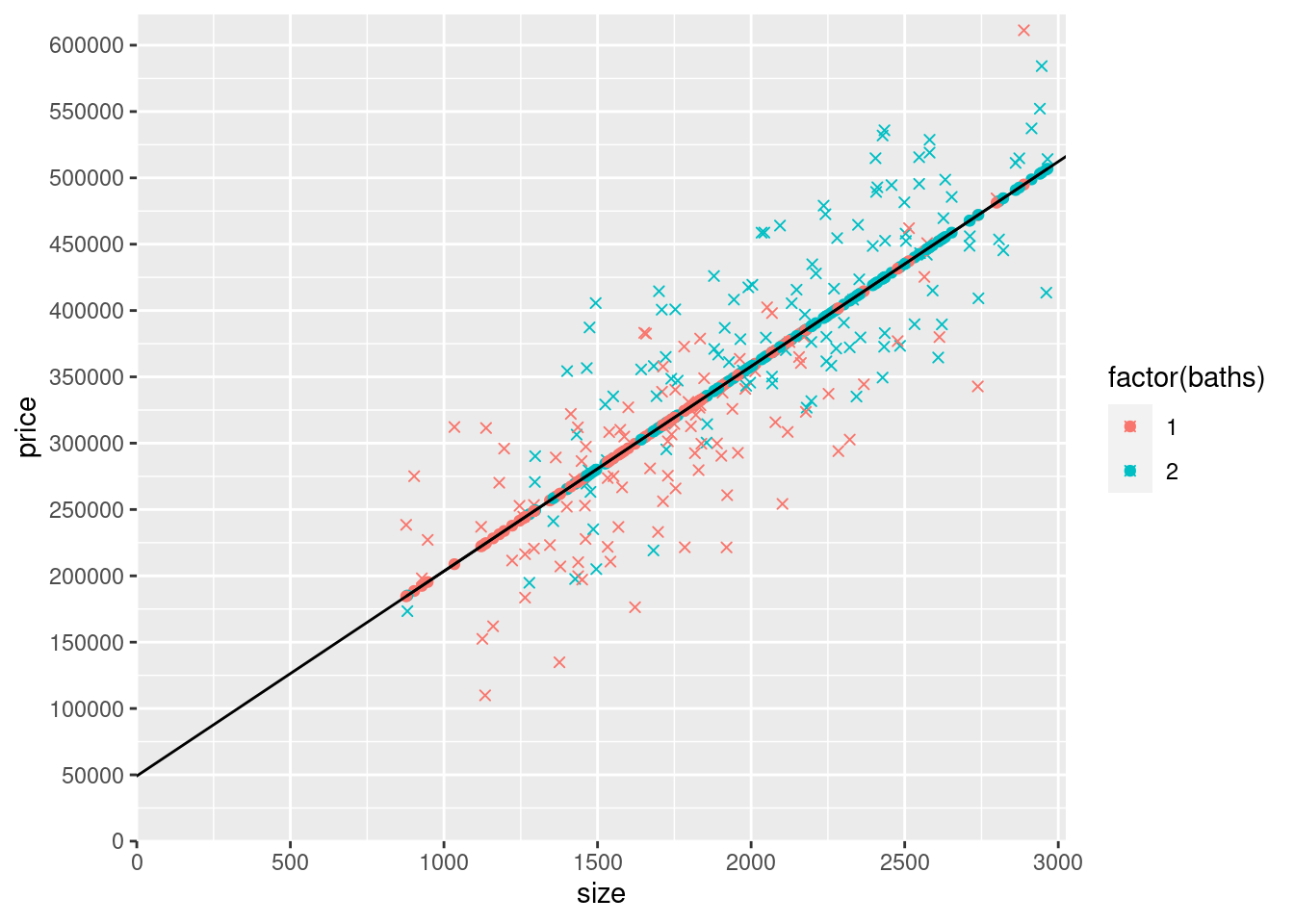
3) The slope of yHatS is the effect of size (of an additional \(ft^2\)) on the predicted price from the model that only controls for size. What do you think will happen to the effect of size on the predicted price when we also control for baths?
YOUR ANSWER HERE
I think that the effect of size on predicted price will decrease when we control for the number of baths. I would assume that bigger houses tend to have more bathrooms, and as a result without accounting for bathrooms in our model, we are over estimating the effect that square feet have an the expected price of a home.
12.3 Number of bathrooms and size
4) Now add the number of bathrooms (baths) as a variable to the regression (in addition to size) and store the model as modelSB (“model” with “S” for size and “B” for baths). Display the output using pander. Add a variable yHatSB to mydata with the predicted prices from this model. Remember that for this model (the “SB” model that includes both size and baths), predicted prices are given by:
\[
\hat{y} = \hat{\beta}_0 + \hat{\beta}_1 size + \hat{\beta}_2 baths
\]
Hint: Start by copy/pasting the code above where you estimated modelS and added yHatS to mydata. However, make sure to change the R object references when you use them, e.g., change modelS to modelSB. If you don’t, you’ll either have the wrong values (e.g., use the coefficient on size from the wrong model), or get an error (e.g., try to use the coefficient on baths from modelS that doesn’t include baths). Also make sure to change variable names in the expression calculating yHat (e.g., make sure the size coefficient is multiplied by the size variable, and the baths coefficient is multiplied by the baths variable…otherwise you might not notice here, but later your graph might not work).
YOUR ANSWER HERE
| Estimate | Std. Error | t value | Pr(>|t|) | |
|---|---|---|---|---|
| (Intercept) | 20004 | 15384 | 1.3 | 0.1949 |
| size | 136.3 | 7.944 | 17.16 | 5.014e-42 |
| baths | 42005 | 7841 | 5.357 | 0.0000002187 |
| Observations | Residual Std. Error | \(R^2\) | Adjusted \(R^2\) |
|---|---|---|---|
| 216 | 52094 | 0.6967 | 0.6938 |
5) Now let’s add yHatSB to the graph as a scatterplot. Copy the last graph you made above, remove the geom_point() of yHatS, and add a geom_point() of yHatSB. Make the color “orange” for all the yHatSB points (i.e., the new geom_point() should be this: geom_point(data=mydata,aes(y=yHatSB,x=size),col="orange")). By “copy the last graph you made”, I do mean that you should leave the geom_abline that plots the modelS regression line from the previous graph (don’t change it to modelSB), and leave the axes starting at (0,0).
YOUR ANSWER HERE
ggplot(mydata) +
geom_point(aes(y=price,x=size,col=factor(baths)),shape=4) +
geom_point(aes(y=yHatSB,x=size), col="orange") +
geom_line(aes(y=yHatS,x=size),col="black") +
geom_abline(intercept=coef(modelS)["(Intercept)"],slope=coef(modelS)["size"], col = "black") + scale_x_continuous(expand = c(0, 0),limits = c(0, max(mydata$size)*1.02),breaks = seq(0,max(mydata$size)*1.02,500)) +
scale_y_continuous(expand = c(0, 0),limits = c(0, max(mydata$price)*1.02), breaks = seq(0,max(mydata$price)*1.02,50000))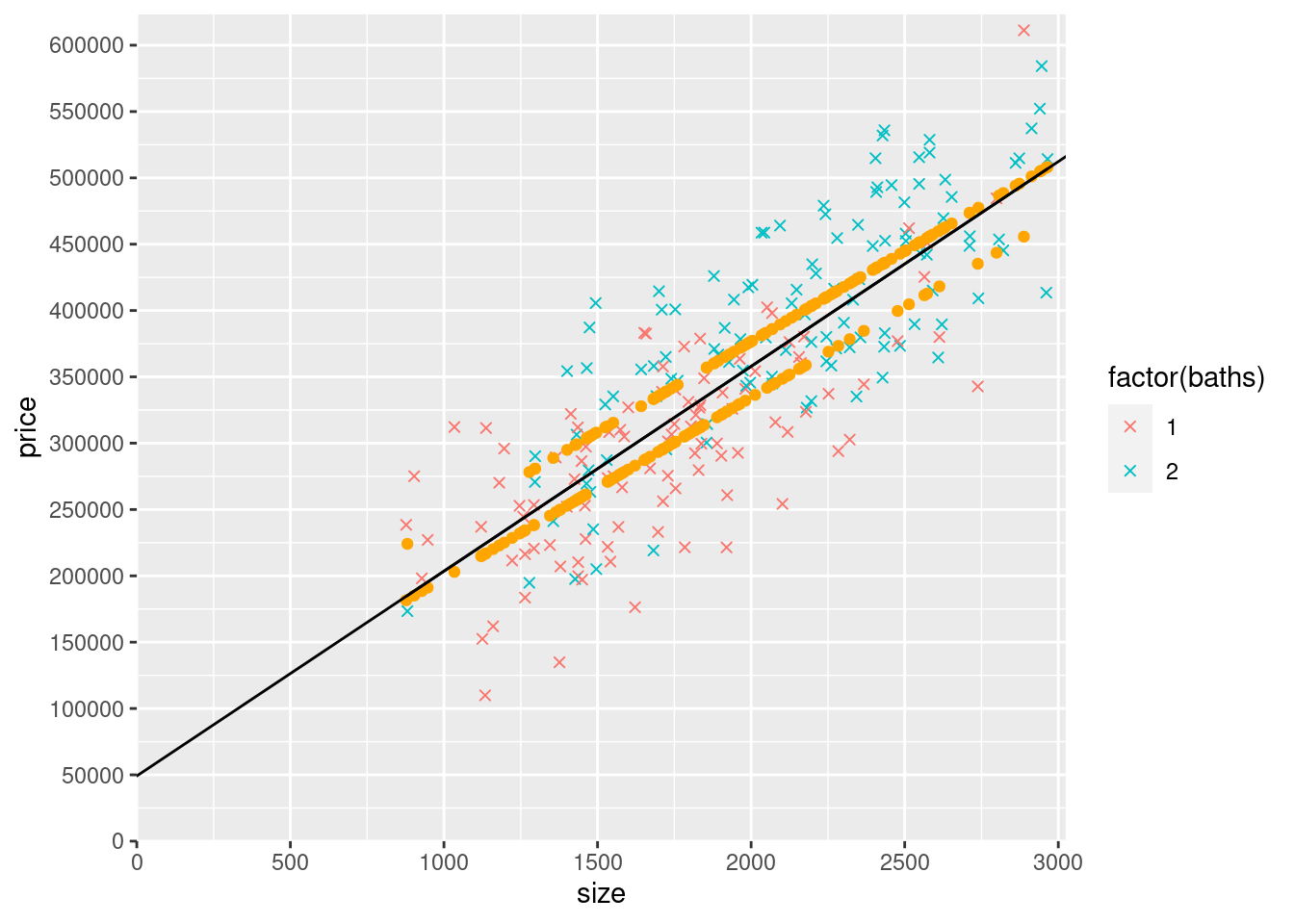
6) It looks like there are two upward-sloping parallel rows of yHatSB predicted prices. What accounts for the general upward slope of the yHatSB predicted prices? Why are there two rows (try looking at a count() of baths to help you answer this part of the question)?
YOUR ANSWER HERE
## baths n
## 1 1 102
## 2 2 114There reason there are two rows for yHatSB is because there are only 2 values for baths, 1 or 2. The reason the lines are parallel is because there isn’t an interaction between the coefficient for square-feet and baths, meaning that the rate at which house prices increase per-square foot is the same for 1 bath and 2 bath houses. The reason the slope is upward sloping is that as the size of the house increases, the price increases.
7) Look at the graph you just made. Notice that the yHatS line doesn’t go straight through the middle of the two rows of yHatSB predicted prices. What is the slope of the yHatS line (the answer is one of the coefficients estimated above)? What is the slope of the two rows of yHatSB predicted prices (the answer is a coefficient estimated above)? Which slope is steeper? What accounts for the difference between these different slopes?
YOUR ANSWER HERE
the slope in yHatS is 154.37 and the slope of the two lines in the yHatSB model is 136.32. The slope in yHatS is steeper than the slope in yHatSB. This is because the model in yHatSB accounts for the difference in price due to the number of bathrooms, and yHatS doesn’t. Since houses with more bathrooms tend to cost more than houses with fewer bathrooms, yHatS allows \(ft^2\) to have a greater impact on house price than it actually does becuase the model can’t attribute to price discrepency to bathrooms.
8) How far apart vertically in the y direction (the price direction) are the two rows of yHatSB predicted prices? Why?
YOUR ANSWER HERE
The two rows of yHatSB are 42004.73 dollars apart. This is because there are only two values for baths, 1 or 2, so the houses with 1 bathroom fall on the lower line, and the houses with 2 bathrooms fall on the higher line. The difference itself is due to the the fact that holding the size of the house constant, we expect houses with 2 bathrooms to cost 42004.73 more than a house with only one bathroom.
9) Now you’re going to create a new version of the graph above, except all the points on the lower row of orange dots are going to be red (and connected by a red line) and all the points on the upper row of orange dots are going to be blue (and connected by a blue line). Copy the code from the previous graph as the basis for making the graph. But before creating the new graph, you’ll need to create a few new variables that you can use to replace parts of the original graph. Here’s what you need to do:
Using only the coefficients from modelSB and the size variable (and simple arithmetic), generate a variable name yHatSB1 that when you plot it, replaces the lower row of yHatSB predicted price points. Make sure that these points are only created for observations with 1 bathroom and are NA for other observation (I’d use ifelse() for baths==1). In other words, do something like this:
mydata$yHatSB1 <- ifelse(mydata$baths == 1, coef(modelSB)["(Intercept)"] + coef(modelSB)["baths"]*1 + coef(modelSB)["size"]*mydata$size, NA)
Add these yHatSB1 points to the graph as geom_point() and make them dots red. Also add a geom_abline() that goes through this row of dots and make it a red line. To do this, think about what part(s) of the yHatSB1 line are the intercept and what part(s) are the slope on a graph that has size on the x axis.
Do the same thing for the upper row. In other words, also using only the coefficients from modelSB and the size variable (and simple arithmetic), generate a variable name yHatSB2 that when you plot it, replaces the upper row of yHatSB predicted price points. Make sure that these points are only created for observations with 2 bathrooms and are NA for other observation (use a similar ifelse() but for baths==2 and calculating the correct yHat values for 2 bathrooms). Add these to the graph as geom_point() and make these dots blue. Also add a geom_abline() that goes through this row of dots and make this line blue.
In addition, remove the orange yHatSB points you added before (because you’ve replaced them with red points and blue points).
In mine, I also labeled the y-intercepts of the three lines (the black line that connects the yHatS points, the red line that connects the yHatSB1 points, and the blue line that connects the yHatSB2 points). To do this, you modify the breaks argument of scale_y_continuous(). Try it if you have time, but don’t waste much time trying to figure this out. Either way, you should understand how the intercepts correspond with coefficients from the models.
YOUR ANSWER HERE
mydata$yHatSB1 <- ifelse(mydata$baths == 1, coef(modelSB)["(Intercept)"] + coef(modelSB)["baths"]*1 + coef(modelSB)["size"]*mydata$size, NA)
mydata$yHatSB2 <- ifelse(mydata$baths == 2, coef(modelSB)["(Intercept)"] + coef(modelSB)["baths"]*2 + coef(modelSB)["size"]*mydata$size, NA)
ggplot(mydata) +
geom_point(aes(y=price,x=size,col=factor(baths)),shape=4) +
geom_point(aes(y=yHatSB1,x=size), col="red") +
geom_abline(intercept=coef(modelSB)["(Intercept)"] + coef(modelSB)["baths"]*1, slope=coef(modelSB)["size"], col = "red") +
geom_point(aes(y=yHatSB2,x=size), col="blue") +
geom_abline(intercept=coef(modelSB)["(Intercept)"] + coef(modelSB)["baths"]*2, slope=coef(modelSB)["size"], col = "blue") +
geom_abline(intercept=coef(modelS)["(Intercept)"], slope=coef(modelS)["size"], col = "black") +
scale_x_continuous(expand = c(0, 0),limits = c(0, max(mydata$size)*1.02),breaks = seq(0,max(mydata$size)*1.02,500)) +
scale_y_continuous(expand = c(0, 0),limits = c(0, max(mydata$price)*1.02), breaks = seq(0,max(mydata$price)*1.02,50000))## Warning: Removed 114 rows containing missing values (`geom_point()`).## Warning: Removed 102 rows containing missing values (`geom_point()`).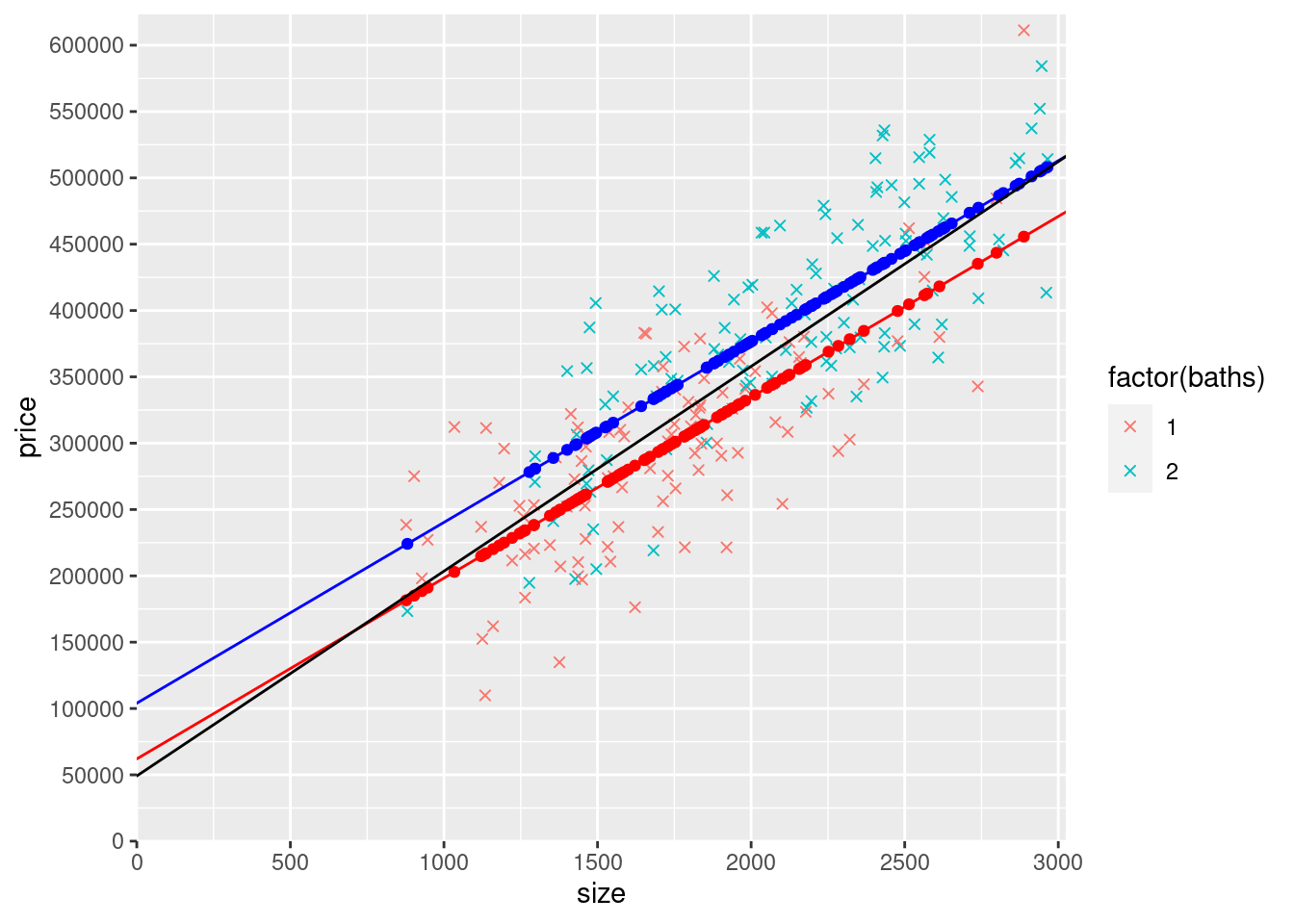
10) Using ifelse(), create two dummy variables, baths1 and baths2, and add them to mydata. The variable baths1 equals 1 for houses with 1 bathroom and equals 0 otherwise. The variable baths2 equals 1 for houses with 2 bathroom and equals 0 otherwise. Make sure to look at the data after creating the variables to make sure you did it correctly (e.g., use head())! Calculate the mean of baths1 and baths2. What does the mean of baths1 tell us? What about the mean of baths2?
YOUR ANSWER HERE
mydata <- mydata %>%
mutate(baths1 = ifelse(baths == 1, 1, 0)) %>%
mutate(baths2 = ifelse(baths == 2, 1, 0))
mydata %>%
summarize(mean_baths1 = mean(baths1), mean_baths2 = mean(baths2)) %>%
head()## mean_baths1 mean_baths2
## 1 0.4722222 0.5277778The mean of baths1 tells us what percent of houses have 1 bath, and the mean of baths 2 tells us what percent of houses have 2 baths.
11) Try estimating a regression (with price as the y variable) that includes size, baths1, and baths2. Call it model12. Display the output using pander, but also display coef(model12). Why is part of coef(model12) NA? Why? Hint: which of the 4 MLR assumptions is violated?
YOUR ANSWER HERE
| Estimate | Std. Error | t value | Pr(>|t|) | |
|---|---|---|---|---|
| (Intercept) | 104013 | 17658 | 5.89 | 0.00000001487 |
| size | 136.3 | 7.944 | 17.16 | 5.014e-42 |
| baths1 | -42005 | 7841 | -5.357 | 0.0000002187 |
| Observations | Residual Std. Error | \(R^2\) | Adjusted \(R^2\) |
|---|---|---|---|
| 216 | 52094 | 0.6967 | 0.6938 |
## (Intercept) size baths1 baths2
## 104013.3696 136.3161 -42004.7326 NAThe reason baths2 has an NA is because baths1 measures the difference in price between houses with one bath and 2 baths, holding size constant, so adding baths 2 would be the same as adding baths 1. This would give us perfect collinearity, which we can’t have, so the model spits out an NA because we cant use it.
12) Since we cannot include both baths1 and baths2 in the regression, lets try again without baths1. Estimate a model (name it modelInterceptDummy) that includes size and baths2, but leave out baths1. Display the results in a stargazer table next to the results of modelSB. What is the interpretation of \(\hat{\beta}_0\), \(\hat{\beta}_1\), and \(\hat{\beta}_2\) in modelInterceptDummy)?
How do these coefficients compare/correspond with coefficients from modelSB? Specifically, how does the effect of size compare? What coefficient(s) from each model give you the intercepts for one and two bathroom houses (i.e., the average price when size is 0 for houses with 1 bathroom and for houses with 2 bathrooms)?
YOUR ANSWER HERE
| Estimate | Std. Error | t value | Pr(>|t|) | |
|---|---|---|---|---|
| (Intercept) | 62009 | 14586 | 4.251 | 0.00003181 |
| size | 136.3 | 7.944 | 17.16 | 5.014e-42 |
| baths2 | 42005 | 7841 | 5.357 | 0.0000002187 |
| Observations | Residual Std. Error | \(R^2\) | Adjusted \(R^2\) |
|---|---|---|---|
| 216 | 52094 | 0.6967 | 0.6938 |
stargazer(model12, modelInterceptDummy,
type = "html",
report=('vc*p'),
keep.stat = c("n","rsq","adj.rsq"),
notes = "<em>*p<0.1;**p<0.05;***p<0.01</em>",
notes.append = FALSE)| Dependent variable: | ||
| price | ||
| (1) | (2) | |
| size | 136.316*** | 136.316*** |
| p = 0.000 | p = 0.000 | |
| baths1 | -42,004.730*** | |
| p = 0.00000 | ||
| baths2 | 42,004.730*** | |
| p = 0.00000 | ||
| Constant | 104,013.400*** | 62,008.640*** |
| p = 0.000 | p = 0.00004 | |
| Observations | 216 | 216 |
| R2 | 0.697 | 0.697 |
| Adjusted R2 | 0.694 | 0.694 |
| Note: | *p<0.1;**p<0.05;***p<0.01 | |
\(\hat{\beta}_0\) represents that a house of size 0, that has 1 bathroom, we expect the price of the home to be 62008.64. Since homes are not 0 \(ft^2\), this is not a reasonable thing to inturpret.
\(\hat{\beta}_1\) represents that holding the number of baths constant, the price of a home is expected to increase by 136.32 per \(ft^2\). This effect is statistically significant at the 1% level
\(\hat{\beta}_2\) represents that holding the size of the house constant, a house with 2 baths is expected to cost 42004.73 more than a home with one bath. This effect is statistically significant at the 1% level.
Compared with modelSB, the coefficient for size in modelInterceptDummy is the same. baths in modelSB is the same as the coefficient baths2 in modelInterceptDummy. The intercept coefficient in modelInterceptDummy is 62008.64, and modelSB’s is 20003.90. This makes sense though. In modelSB, the intercept gives the expected price of a house that is 0 \(ft^2\) and has one bath room, and in modelInterceptDummy, the intercept gives the expected price of a house that is 0 \(ft^2\) and has 2 bathrooms. This is because modelInterceptDummy has a baseline number of bathrooms of 2, where as modelSB has a baseline number of baths at 1.
13) Create the same graph you created above with the red and blue lines, except modify the geom_abline() layers that use coefficients from modelSB so that they use modelInterceptDummy instead. Leave everything else as it is in the previous graph (e.g., leave the black line geom_abline() that uses modelS, leave the geom_point() using yHatSB1 and yHatSB2). The graph itself should look identical (the two models are identical because the only possible values of baths are 1 and 2). Make sure that your red line (using geom_abline() based on modelInterceptDummy coefficients) actually goes through the red points (the geom_point() based on yHatSB1) and make sure that your blue line (using geom_abline() based on modelInterceptDummy coefficients) actually goes through the blue points (the geom_point() based on yHatSB2).
YOUR ANSWER HERE
ggplot(mydata) +
geom_point(aes(y=price,x=size,col=factor(baths)),shape=4) +
geom_point(aes(y=yHatSB1,x=size), col="red") +
geom_abline(intercept=coef(modelInterceptDummy)["(Intercept)"] + coef(modelInterceptDummy)["baths2"]*0, slope=coef(modelInterceptDummy)["size"], col = "red") +
geom_point(aes(y=yHatSB2,x=size), col="blue") +
geom_abline(intercept=coef(modelInterceptDummy)["(Intercept)"] + coef(modelInterceptDummy)["baths2"]*1, slope=coef(modelInterceptDummy)["size"], col = "blue") +
geom_abline(intercept=coef(modelS)["(Intercept)"], slope=coef(modelS)["size"], col = "black") +
scale_x_continuous(expand = c(0, 0),limits = c(0, max(mydata$size)*1.02),breaks = seq(0,max(mydata$size)*1.02,500)) +
scale_y_continuous(expand = c(0, 0),limits = c(0, max(mydata$price)*1.02), breaks = seq(0,max(mydata$price)*1.02,50000))## Warning: Removed 114 rows containing missing values (`geom_point()`).## Warning: Removed 102 rows containing missing values (`geom_point()`).
12.4 Slope dummy
14) Think about what model would allow for the slope (with respect to size) to be different for 1 and 2 bathroom houses (but for the intercept to be the same). Write out the equation for this model the way equations were written out using latex code above (e.g., using \(\beta_1\) etc).
YOUR ANSWER HERE
\[ \hat{y} = \hat{\beta}_0 + \hat{\beta}_1 size + \hat{\beta}_2(baths2*size) \]
Create any new variables you need to create, and then estimate the model and call it modelSlopeDummy.
YOUR ANSWER HERE
Display the results of modelS, modelInterceptDummy, and modelSlopeDummy side-by-side using stargazer.
YOUR ANSWER HERE
stargazer(modelS, modelInterceptDummy, modelSlopeDummy,
type = "html",
report=('vc*p'),
keep.stat = c("n","rsq","adj.rsq"),
notes = "<em>*p<0.1;**p<0.05;***p<0.01</em>",
notes.append = FALSE)| Dependent variable: | |||
| price | |||
| (1) | (2) | (3) | |
| size | 154.373*** | 136.316*** | 124.733*** |
| p = 0.000 | p = 0.000 | p = 0.000 | |
| baths2 | 42,004.730*** | ||
| p = 0.00000 | |||
| size2 | 21.572*** | ||
| p = 0.00000 | |||
| Constant | 49,173.680*** | 62,008.640*** | 82,310.930*** |
| p = 0.002 | p = 0.00004 | p = 0.00000 | |
| Observations | 216 | 216 | 216 |
| R2 | 0.656 | 0.697 | 0.697 |
| Adjusted R2 | 0.654 | 0.694 | 0.695 |
| Note: | *p<0.1;**p<0.05;***p<0.01 | ||
Create a graph similar to what you did above, except using this new model. Start with the previous graph and make the following changes:
Remove the black line based on
modelS.Remove the red
geom_point()based onyHatSB1and replace it with redgeom_point()based onmodelSlopeDummy(I suggest creating ayHatSlopeDummy1similar to how you createdyHatSB1).Remove the blue
geom_point()based onyHatSB2and replace it with bluegeom_point()based onmodelSlopeDummy(I suggest creating ayHatSlopeDummy2similar to how you createdyHatSB2).Remove the red
geom_abline()based onmodelInterceptDummyand replace it with a redgeom_abline()based on the coefficients frommodelSlopeDummy.Remove the blue
geom_abline()based onmodelInterceptDummyand replace it with a redgeom_abline()based on the coefficients frommodelSlopeDummy.
NOTE: you rarely want to estimate a model with a slope dummy unless you also have the corresponding intercept dummy (see the next question for that model), but I’m having you do so now because it’s your first one and you need to learn how to do so.
YOUR ANSWER HERE
mydata$yHatSlopeDummy1 <- ifelse(mydata$baths == 1, coef(modelSlopeDummy)["(Intercept)"] + coef(modelSlopeDummy)["size2"]*0 + coef(modelSlopeDummy)["size"]*mydata$size, NA)
mydata$yHatSlopeDummy2 <- ifelse(mydata$baths == 2, coef(modelSlopeDummy)["(Intercept)"] + coef(modelSlopeDummy)["size2"]*mydata$size2 + coef(modelSlopeDummy)["size"]*mydata$size, NA)
ggplot(mydata) +
geom_point(aes(y=price,x=size,col=factor(baths)),shape=4) +
geom_point(aes(y=yHatSlopeDummy1,x=size), col="red") +
geom_abline(intercept=coef(modelSlopeDummy)["(Intercept)"], slope=coef(modelSlopeDummy)["size"] + coef(modelSlopeDummy)["size2"]*0, col = "red") +
geom_point(aes(y=yHatSlopeDummy2,x=size), col="blue") +
geom_abline(intercept=coef(modelSlopeDummy)["(Intercept)"], slope=coef(modelSlopeDummy)["size"] + coef(modelSlopeDummy)["size2"]*1, col = "blue") +
scale_x_continuous(expand = c(0, 0),limits = c(0, max(mydata$size)*1.02),breaks = seq(0,max(mydata$size)*1.02,500)) +
scale_y_continuous(expand = c(0, 0),limits = c(0, max(mydata$price)*1.02), breaks = seq(0,max(mydata$price)*1.02,50000))## Warning: Removed 114 rows containing missing values (`geom_point()`).## Warning: Removed 102 rows containing missing values (`geom_point()`).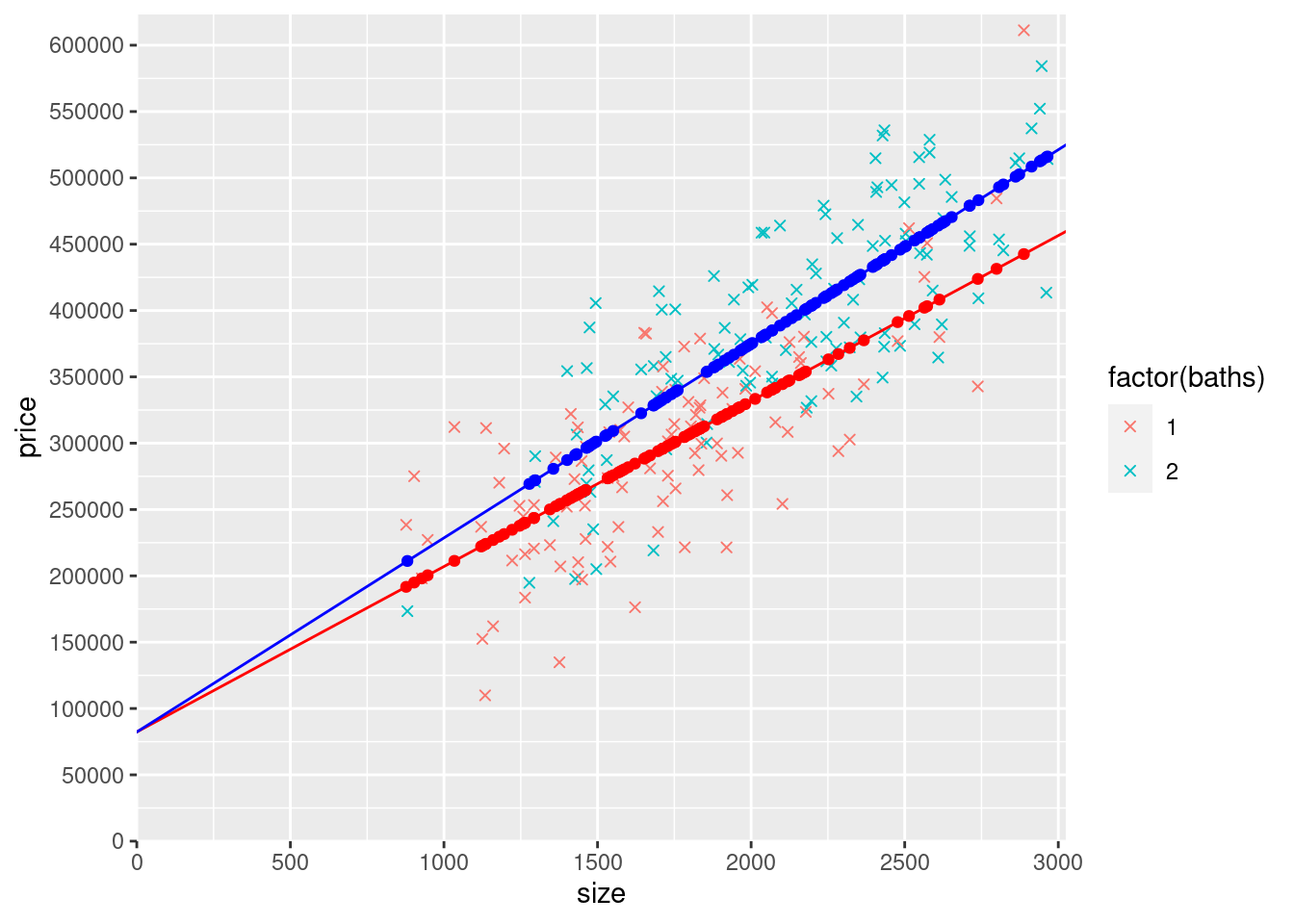
12.5 Intercept and slope dummies
15) Estimate a model that allows for both the intercept and the slope (with respect to size) to be different for 1 and 2 bathroom houses.
Write out the equation for this model the way equations were written out using latex code above (e.g., using \(\beta_1\), etc).
YOUR ANSWER HERE
\[ \hat{y} = \hat{\beta}_0 + \hat{\beta}_1 size + \hat{\beta}_2 baths2 + \hat{\beta}_3 (baths2*size) \]
Create any new variables you need to create, if you need to create any, and then estimate the model and call it modelSlopeAndInterceptDummies.
YOUR ANSWER HERE
modelSlopeAndInterceptDummies <- lm(price~ size + baths2 + size2, data = mydata)
pander(summary(modelSlopeAndInterceptDummies))| Estimate | Std. Error | t value | Pr(>|t|) | |
|---|---|---|---|---|
| (Intercept) | 75489 | 21120 | 3.574 | 0.0004349 |
| size | 128.5 | 11.92 | 10.77 | 7.231e-22 |
| baths2 | 15120 | 31443 | 0.4809 | 0.6311 |
| size2 | 14.12 | 16 | 0.8829 | 0.3783 |
| Observations | Residual Std. Error | \(R^2\) | Adjusted \(R^2\) |
|---|---|---|---|
| 216 | 52121 | 0.6978 | 0.6935 |
Display the results of the four models (modelS, modelInterceptDummy, modelSlopeDummy, and modelSlopeAndInterceptDummies) side-by-side using stargazer. For this part though, do it below the graph instead of here.
Create a graph of this model by following the same steps you followed above to create the graph of the slope dummy model.
YOUR ANSWER HERE
mydata$yHatSlopeandInterceptDummy1 <- ifelse(mydata$baths == 1, coef(modelSlopeAndInterceptDummies)["(Intercept)"] + coef(modelSlopeAndInterceptDummies)["size2"]*0 + coef(modelSlopeAndInterceptDummies)["size"]*mydata$size + coef(modelSlopeAndInterceptDummies)["baths2"]*0, NA)
mydata$yHatSlopeandInterceptDummy2 <- ifelse(mydata$baths == 2, coef(modelSlopeAndInterceptDummies)["(Intercept)"] + coef(modelSlopeAndInterceptDummies)["size2"]*mydata$size2 + coef(modelSlopeAndInterceptDummies)["size"]*mydata$size + coef(modelSlopeAndInterceptDummies)["baths2"]*1, NA)
ggplot(mydata) +
geom_point(aes(y=price,x=size,col=factor(baths)),shape=4) +
geom_point(aes(y=yHatSlopeandInterceptDummy1,x=size), col="red") +
geom_abline(intercept=coef(modelSlopeAndInterceptDummies)["(Intercept)"] + coef(modelSlopeAndInterceptDummies)["baths2"]*0, slope=coef(modelSlopeAndInterceptDummies)["size"] + coef(modelSlopeAndInterceptDummies)["size2"]*0, col = "red") +
geom_point(aes(y=yHatSlopeandInterceptDummy2,x=size), col="blue") +
geom_abline(intercept=coef(modelSlopeAndInterceptDummies)["(Intercept)"] + coef(modelSlopeAndInterceptDummies)["baths2"]*1, slope=coef(modelSlopeAndInterceptDummies)["size"] + coef(modelSlopeAndInterceptDummies)["size2"]*1, col = "blue") +
scale_x_continuous(expand = c(0, 0),limits = c(0, max(mydata$size)*1.02),breaks = seq(0,max(mydata$size)*1.02,500)) +
scale_y_continuous(expand = c(0, 0),limits = c(0, max(mydata$price)*1.02), breaks = seq(0,max(mydata$price)*1.02,50000))## Warning: Removed 114 rows containing missing values (`geom_point()`).## Warning: Removed 102 rows containing missing values (`geom_point()`).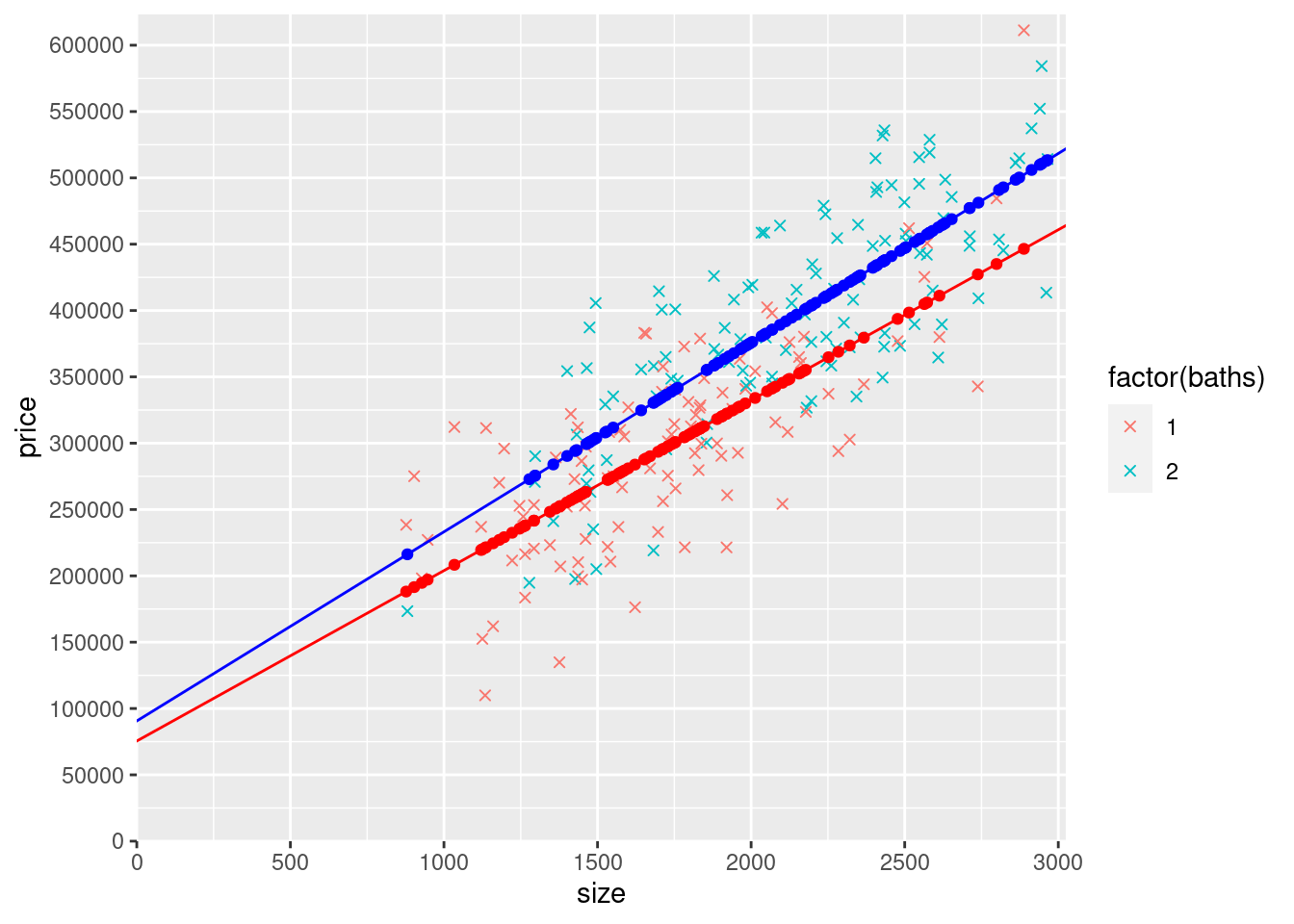
16) Display the stargazer table comparing the four models (modelS, modelInterceptDummy, modelSlopeDummy, and modelSlopeAndInterceptDummies).
YOUR ANSWER HERE
stargazer(modelS, modelInterceptDummy, modelSlopeDummy, modelSlopeAndInterceptDummies,
type = "html",
report=('vc*p'),
keep.stat = c("n","rsq","adj.rsq"),
notes = "<em>*p<0.1;**p<0.05;***p<0.01</em>",
notes.append = FALSE)| Dependent variable: | ||||
| price | ||||
| (1) | (2) | (3) | (4) | |
| size | 154.373*** | 136.316*** | 124.733*** | 128.467*** |
| p = 0.000 | p = 0.000 | p = 0.000 | p = 0.000 | |
| baths2 | 42,004.730*** | 15,120.010 | ||
| p = 0.00000 | p = 0.632 | |||
| size2 | 21.572*** | 14.123 | ||
| p = 0.00000 | p = 0.379 | |||
| Constant | 49,173.680*** | 62,008.640*** | 82,310.930*** | 75,489.050*** |
| p = 0.002 | p = 0.00004 | p = 0.00000 | p = 0.0005 | |
| Observations | 216 | 216 | 216 | 216 |
| R2 | 0.656 | 0.697 | 0.697 | 0.698 |
| Adjusted R2 | 0.654 | 0.694 | 0.695 | 0.694 |
| Note: | *p<0.1;**p<0.05;***p<0.01 | |||
Using the estimated coefficients from the four models, write out the equation for the predicted prices for each of the four models, followed by the conditional expectations for each of the four models for one bathroom houses, followed by the conditional expectations for each of the four models for one bathroom houses. I filled in each of these for the first model (the one with size only) for you so you can see what I’m asking you to do. You can copy/paste what I did and then modify it for the subsequent models (modelInterceptDummy, modelSlopeDummy, and modelSlopeAndInterceptDummies). Round all coefficients to 0 decimal places they way I did for modelS.
YOUR ANSWER HERE
Predicted prices from the four models: \[ \begin{aligned} \widehat{price} &= 49174 + 154 \cdot size \\ \widehat{price} &= 62009 + 136 \cdot size + 42005 \\ \widehat{price} &= 82311 + 125 \cdot size + 22 \cdot size2 \\ \widehat{price} &= 75489 + 128 \cdot size + 15120 + 14 \cdot size2 \end{aligned} \]
Expected prices for 1 bathroom (not-two bathroom) houses \[ \begin{aligned} E(price|size,baths2=0) &= 49174 + 154 \cdot size \\ E(price|size,baths2=0) &= 62009 + 136 \cdot size + 42005 \cdot 0 \\ E(price|size,baths2=0) &= 82311 + 125 \cdot size + 22 \cdot 0 \\ E(price|size,baths2=0) &= 75489 + 128 \cdot size + 15120 \cdot 0 + 14 \cdot 0 \end{aligned} \]
Expected prices for two bathroom houses \[ \begin{aligned} E(price|size,baths2=1) &= 49174 + 154 \cdot size \\ E(price|size,baths2=1) &= 62009 + 136 \cdot size + 42005 \\ E(price|size,baths2=1) &= 82311 + 125 \cdot size + 22 \cdot size2 \\ E(price|size,baths2=1) &= 75489 + 128 \cdot size + 15120 + 14 \cdot size2 \end{aligned} \]
17) What do you notice about the intercepts and the slopes? Think about what variation each model allows and what restrictions it imposes. Why are the intercepts furthest out for the model with the intercept dummy (modelInterceptDummy), at one point in the middle for the model with the slope dummy, and in between for the model with both the intercept and slope dummies? How does that relate to the estimated slopes? How does that relate to the model that only includes size? I’d start by comparing the graphs of the models.
YOUR ANSWER HERE
The models with multiple slope terms have slopes closer to the 0, this is because the number of baths a house has impacts how much house price is expected to increase per \(ft^2\). Models that don’t account for this must have houses with two baths cost more some how, but instead of allowing the expect house price in a home with 2 baths to increase by more per \(ft^2\) than a house with 1 bath per \(ft^2\), it costs the same amount more at each \(ft^2\), causing the intercept to be higher. The reason that the model with the slope dummy has an intercept in the middle is because houses with one bath and houses with 2 baths are forced to share an intercept, where as in the model with just an intercept dummy, and the model with both slope and intercept dummies, the intercepts are allowed to be different for houses one bath and two baths, as a result the model with only one intercept will be somewhere between models with 2 intercepts because models without 2 intercepts can’t account for the fact that houses just cost a baseline amount more if they have 2 baths, regardless of how many \(ft^2\) the house is. As a result, the model with only one intercept will have steeper slopes than models with 2 intercepts, because it attributes all of the difference in price to the fact that houses with two baths increase in price faster per \(ft^2\) than one bath houses, unlike in models with 2 intercepts where the difference in price is due to that, and the fact that two bath houses just cost more because they have an extra bath.
12.6 Models with the number of bedrooms
18) To help you gain additional intuition for what’s going on in linear regressions, try estimating a model that includes size and the number of bedrooms (beds). Make a plot that includes yHat predicted values. Color the yHat points based on the number of bedrooms (use 1 bedroom = red, 2 bedroom = orange, 3 bedroom = green, 4 bedroom = blue….why? because people are used to seeing rainbow order, but yellow is hard to see so we skipped it…you can do this by adding scale_color_manual(values=c("red", "orange", "green","blue")). Why are the yHat points arranged in rows? How many rows are there? Why? Add geom_abline()s that connect the rows of dots (using the same colors as the yHat points).
Note that this is 4 separate geom_abline()s. It makes for a lot of lines of code. However, remember that once you do one of them, the other three are easily obtained by copy/pasting the first and changing the number of bedrooms and the corresponding color.
YOUR ANSWER HERE
| Estimate | Std. Error | t value | Pr(>|t|) | |
|---|---|---|---|---|
| (Intercept) | 69942 | 17390 | 4.022 | 0.00008013 |
| size | 113.8 | 18.4 | 6.184 | 0.000000003146 |
| beds | 22009 | 9103 | 2.418 | 0.01645 |
| Observations | Residual Std. Error | \(R^2\) | Adjusted \(R^2\) |
|---|---|---|---|
| 216 | 54747 | 0.665 | 0.6619 |
mydata$yHatS <- coef(modelSBed)["(Intercept)"] + coef(modelSBed)["size"] * mydata$size + coef(modelSBed)["beds"] * mydata$beds
ggplot(mydata) +
geom_point(aes(y=price,x=size, col=factor(beds)), shape = 4) + scale_color_manual(values=c("red", "orange", "green","blue")) +
geom_point(aes(y=yHatS,x=size, col=factor(beds))) + scale_color_manual(values=c("red", "orange", "green","blue")) +
geom_abline(intercept=coef(modelSBed)["(Intercept)"] + coef(modelSBed)["beds"]*1,slope=coef(modelSBed)["size"], col = "red") +
geom_abline(intercept=coef(modelSBed)["(Intercept)"] + coef(modelSBed)["beds"]*2,slope=coef(modelSBed)["size"], col = "orange") +
geom_abline(intercept=coef(modelSBed)["(Intercept)"] + coef(modelSBed)["beds"]*3,slope=coef(modelSBed)["size"], col = "green") +
geom_abline(intercept=coef(modelSBed)["(Intercept)"] + coef(modelSBed)["beds"]*4,slope=coef(modelSBed)["size"], col = "blue")## Scale for colour is already present.
## Adding another scale for colour, which will replace the existing scale.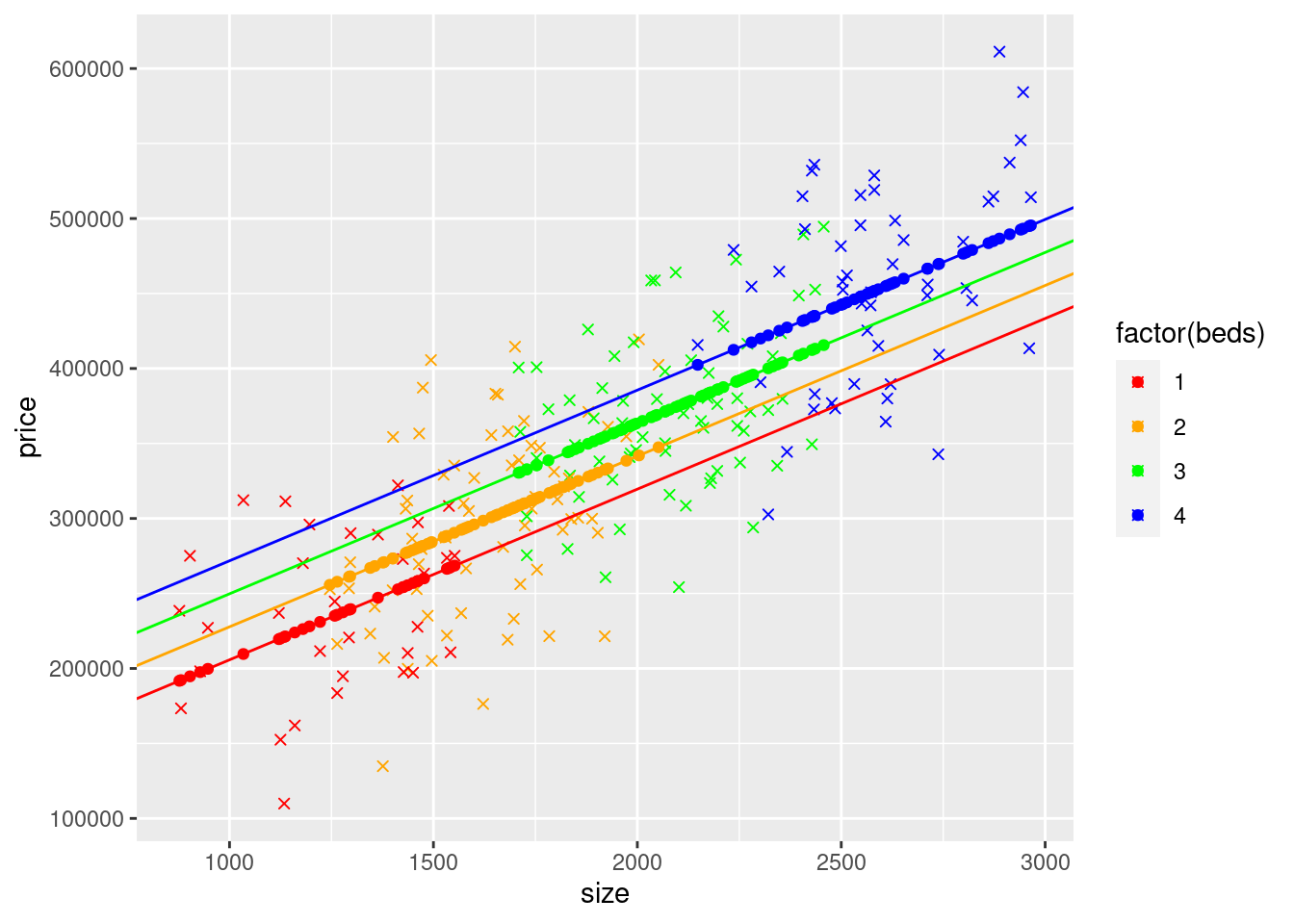
The reason that the predicted points are plotted in rows is because adding beds to the model doesn’t affect the slope, the model just says that for each additional bedroom a house has, the house will cost 22009.10 more, holding \(ft^2\) constant. beds just changes the intercept, meaning houses with different numbers of bedrooms all have the same slope. The reason the lines are evenly spaced is because the way we put the variable beds into the model forces the change in price to be the same for all numbers of beds, in other words a move from 1 to 2 beds is the same as 3 to 4 holding \(ft^2\) constant.
19) Now try changing the previous model to include factor(beds) instead of beds (alternatively, create a dummy variable for 2 bedroom houses, 3 bedroom houses, and 4 bedroom houses, and include these three dummy variables in the model). Make a plot that includes yHat predicted values. Color the yHat points based on the number of bedrooms (using the same colors as above). Why are the yHat points arranged in rows? How many rows are there? Why? Can you add geom_abline()s that connect the rows of dots? How do the rows of dots (and the geom_abline()s that connect them) compare with the previous model? Is the effect of going from 1 bedroom to 2, or 2 to 3, or 3 to 4 different in this model than in the first?
YOUR ANSWER HERE
KEEP WORKING HERE
mydata <- mydata %>%
mutate(beds1 = ifelse(beds == 1, 1, 0)) %>%
mutate(beds2 = ifelse(beds == 2, 1, 0)) %>%
mutate(beds3 = ifelse(beds == 3, 1, 0)) %>%
mutate(beds4 = ifelse(beds == 4, 1, 0))
modelSBedDummy <- lm(price~size+beds2+beds3+beds4,data=mydata)
pander(summary(modelSBedDummy))| Estimate | Std. Error | t value | Pr(>|t|) | |
|---|---|---|---|---|
| (Intercept) | 98518 | 25537 | 3.858 | 0.000152 |
| size | 111.7 | 18.75 | 5.956 | 0.00000001066 |
| beds2 | 17174 | 13691 | 1.254 | 0.2111 |
| beds3 | 39851 | 19369 | 2.057 | 0.04087 |
| beds4 | 67649 | 27898 | 2.425 | 0.01616 |
| Observations | Residual Std. Error | \(R^2\) | Adjusted \(R^2\) |
|---|---|---|---|
| 216 | 54947 | 0.6657 | 0.6594 |
mydata$yHatSDummy1 <- ifelse(mydata$beds == 1, coef(modelSBedDummy)["(Intercept)"] + coef(modelSBedDummy)["size"] * mydata$size, NA)
mydata$yHatSDummy2 <- ifelse(mydata$beds == 2, coef(modelSBedDummy)["(Intercept)"] + coef(modelSBedDummy)["size"] * mydata$size + coef(modelSBedDummy)["beds2"] * 1, NA)
mydata$yHatSDummy3 <- ifelse(mydata$beds == 3 ,coef(modelSBedDummy)["(Intercept)"] + coef(modelSBedDummy)["size"] * mydata$size + coef(modelSBedDummy)["beds3"] * 1, NA)
mydata$yHatSDummy4 <- ifelse(mydata$beds == 4, coef(modelSBedDummy)["(Intercept)"] + coef(modelSBedDummy)["size"] * mydata$size + coef(modelSBedDummy)["beds4"] * 1, NA)
ggplot(mydata) +
geom_point(aes(y=price,x=size, col=factor(beds)), shape = 4) + scale_color_manual(values=c("red", "orange", "green","blue")) +
geom_point(aes(y=yHatSDummy1,x=size), col = "red") +
geom_point(aes(y=yHatSDummy2,x=size), col = "orange") +
geom_point(aes(y=yHatSDummy3,x=size), col = "green") +
geom_point(aes(y=yHatSDummy4,x=size), col = "blue") +
geom_abline(intercept=coef(modelSBedDummy)["(Intercept)"] + coef(modelSBedDummy)["beds2"]*0 + coef(modelSBedDummy)["beds3"]*0 + coef(modelSBedDummy)["beds4"]*0,slope=coef(modelSBedDummy)["size"], col = "red") +
geom_abline(intercept=coef(modelSBedDummy)["(Intercept)"] + coef(modelSBedDummy)["beds2"]*1 + coef(modelSBedDummy)["beds3"]*0 + coef(modelSBedDummy)["beds4"]*0,slope=coef(modelSBedDummy)["size"], col = "orange") +
geom_abline(intercept=coef(modelSBedDummy)["(Intercept)"] + coef(modelSBedDummy)["beds2"]*0 + coef(modelSBedDummy)["beds3"]*1 + coef(modelSBedDummy)["beds4"]*0,slope=coef(modelSBedDummy)["size"], col = "green") +
geom_abline(intercept=coef(modelSBedDummy)["(Intercept)"] + coef(modelSBedDummy)["beds2"]*0 + coef(modelSBedDummy)["beds3"]*0 + coef(modelSBedDummy)["beds4"]*1,slope=coef(modelSBedDummy)["size"], col = "blue")## Warning: Removed 184 rows containing missing values (`geom_point()`).## Warning: Removed 150 rows containing missing values (`geom_point()`).## Warning: Removed 148 rows containing missing values (`geom_point()`).## Warning: Removed 166 rows containing missing values (`geom_point()`).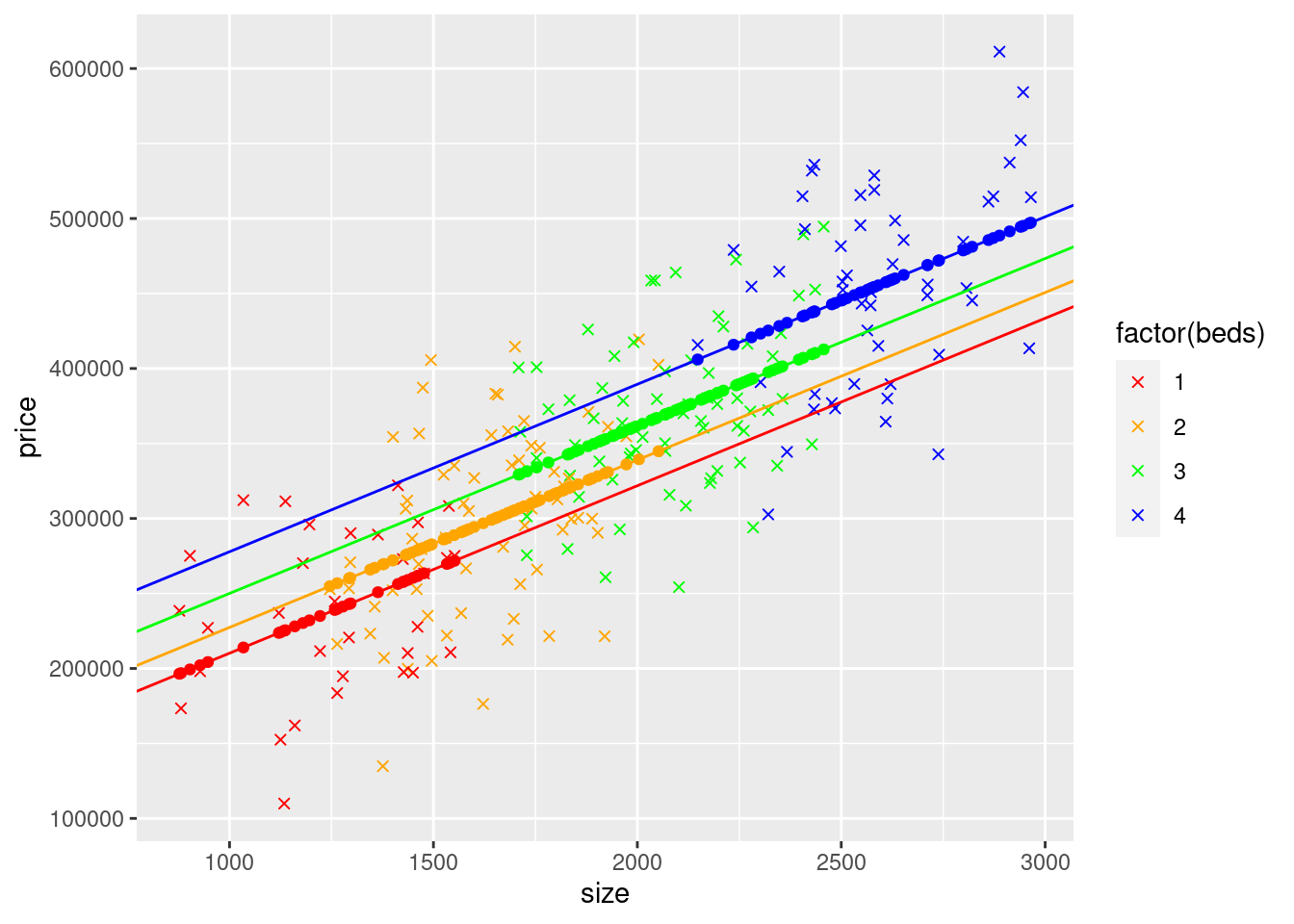
The yHat points are arranged in rows for the same reason as in the model above, the model only changes the intercepts of the lines, not the slopes, so you get 4 parallel lines, one for each number of bed rooms. the lines are slightly different than the model above. This is because modelSBed makes the changes in intercept be the same for each additional bedroom. So moving from a one bed to a two bed house results in the same change as moving from a 3 bed to a 4 bed house. Since we explicitly allow for each bed count to have different change in intercept, so the difference in the house price for a 1 bed and 2 bed house of the same \(ft^2\) is different than the difference in the house price for a 3 bed and 4 bed house of the same \(ft^2\), ie. the lines aren’t evenly spaced in this model. As a result, the slopes of the lines are slightly different than the model above because of that.
20) Now let’s look at models with the number of bathrooms in addition to size and the number of bedrooms. For this model, include bedrooms as beds. Try to answer the same questions as the first model with bedrooms. Making a plot that includes yHat predicted values. Color the yHat points based on the number of bedrooms (using the same colors as before). Why are the yHat points arranged in rows? How many rows are there? Why? Add geom_abline()s that connect the rows of dots (using the same colors).
Note that this is now 8 separate geom_abline()s, but, as above, this isn’t hard if you copy/paste and just change what needs to be modified.
YOUR ANSWER HERE
| Estimate | Std. Error | t value | Pr(>|t|) | |
|---|---|---|---|---|
| (Intercept) | 38729 | 17445 | 2.22 | 0.02747 |
| size | 101.8 | 17.5 | 5.815 | 0.00000002211 |
| beds | 19000 | 8603 | 2.209 | 0.02828 |
| baths | 40858 | 7788 | 5.246 | 0.0000003751 |
| Observations | Residual Std. Error | \(R^2\) | Adjusted \(R^2\) |
|---|---|---|---|
| 216 | 51626 | 0.7035 | 0.6993 |
mydata$yhatSBedBaths <- coef(modelSBedBath)["(Intercept)"] + coef(modelSBedBath)["size"] * mydata$size + coef(modelSBedBath)["beds"] * mydata$beds + coef(modelSBedBath)["baths"] * mydata$baths
ggplot(mydata) +
geom_point(aes(y=price,x=size, col=factor(beds)), shape = 4) + scale_color_manual(values=c("red", "orange", "green","blue")) +
geom_point(aes(y=yhatSBedBaths,x=size, col=factor(beds))) + scale_color_manual(values=c("red", "orange", "green","blue")) +
geom_abline(intercept=coef(modelSBedBath)["(Intercept)"] + coef(modelSBedBath)["beds"]*1 + coef(modelSBedBath)["baths"]*1,slope=coef(modelSBedBath)["size"], col = "red") +
geom_abline(intercept=coef(modelSBedBath)["(Intercept)"] + coef(modelSBedBath)["beds"]*1 + coef(modelSBedBath)["baths"]*2,slope=coef(modelSBedBath)["size"], col = "red") +
geom_abline(intercept=coef(modelSBedBath)["(Intercept)"] + + coef(modelSBedBath)["baths"]*1 + coef(modelSBedBath)["beds"]*2,slope=coef(modelSBedBath)["size"], col = "orange") +
geom_abline(intercept=coef(modelSBedBath)["(Intercept)"] + + coef(modelSBedBath)["baths"]*2 + coef(modelSBedBath)["beds"]*2,slope=coef(modelSBedBath)["size"], col = "orange") +
geom_abline(intercept=coef(modelSBedBath)["(Intercept)"] + coef(modelSBedBath)["beds"]*3 + coef(modelSBedBath)["baths"]*1 ,slope=coef(modelSBedBath)["size"], col = "green") +
geom_abline(intercept=coef(modelSBedBath)["(Intercept)"] + coef(modelSBedBath)["beds"]*3 + coef(modelSBedBath)["baths"]*2 ,slope=coef(modelSBedBath)["size"], col = "green") +
geom_abline(intercept=coef(modelSBedBath)["(Intercept)"] + coef(modelSBedBath)["beds"]*4 + coef(modelSBedBath)["baths"]*1 ,slope=coef(modelSBedBath)["size"], col = "blue") +
geom_abline(intercept=coef(modelSBedBath)["(Intercept)"] + coef(modelSBedBath)["beds"]*4 + coef(modelSBedBath)["baths"]*2 ,slope=coef(modelSBedBath)["size"], col = "blue")## Scale for colour is already present.
## Adding another scale for colour, which will replace the existing scale.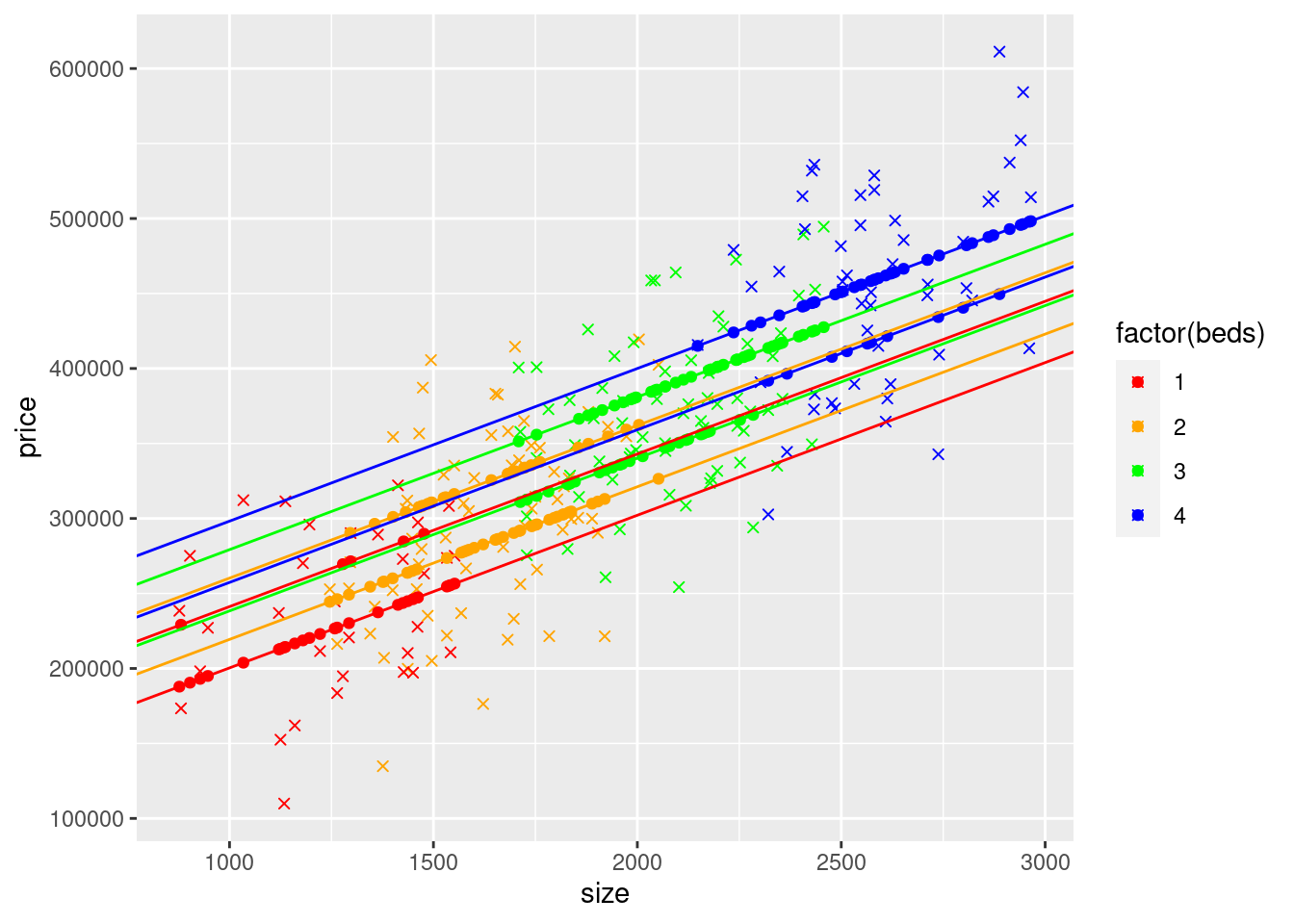 There are 8 rows. The model adjusts the intercept in 4 ways for bed rooms, and in 2 ways for the number of baths, so we have eight rows, one for each combination of bedrooms abd bathrooms.
There are 8 rows. The model adjusts the intercept in 4 ways for bed rooms, and in 2 ways for the number of baths, so we have eight rows, one for each combination of bedrooms abd bathrooms.
21) Finally, try adding baths to the model with factor(beds) and make a similar graph (with the yHat points colored by the number of bedrooms, and the corresponding geom_abline()s). If you understood the previous two questions, you should have no problem understanding this question too. If you didn’t, make sure you understand those models first before trying to wrap your head around this one. How has the spacing between the lines changed? Explain the spacing between the same colored lines (i.e., the same number of bedrooms but 2 bathrooms instead of 1), and the different colored lines (i.e., the number of bedrooms).
YOUR ANSWER HERE
mydata <- mydata %>%
mutate(beds1 = ifelse(beds == 1, 1, 0)) %>%
mutate(beds2 = ifelse(beds == 2, 1, 0)) %>%
mutate(beds3 = ifelse(beds == 3, 1, 0)) %>%
mutate(beds4 = ifelse(beds == 4, 1, 0))
modelSBedDummyBath <- lm(price~size+beds2+beds3+beds4+baths,data=mydata)
pander(summary(modelSBedDummyBath))| Estimate | Std. Error | t value | Pr(>|t|) | |
|---|---|---|---|---|
| (Intercept) | 67253 | 24763 | 2.716 | 0.00716 |
| size | 98.51 | 17.83 | 5.526 | 0.0000000964 |
| beds2 | 10914 | 12946 | 0.8431 | 0.4001 |
| beds3 | 32158 | 18296 | 1.758 | 0.08026 |
| beds4 | 58536 | 26326 | 2.224 | 0.02725 |
| baths | 41370 | 7822 | 5.289 | 0.0000003082 |
| Observations | Residual Std. Error | \(R^2\) | Adjusted \(R^2\) |
|---|---|---|---|
| 216 | 51740 | 0.705 | 0.698 |
mydata$yHatSBedDummyBath1 <- ifelse(mydata$beds == 1, coef(modelSBedDummyBath)["(Intercept)"] + coef(modelSBedDummyBath)["size"] * mydata$size + coef(modelSBedDummyBath)["baths"] * mydata$baths, NA)
mydata$yHatSBedDummyBath2 <- ifelse(mydata$beds == 2, coef(modelSBedDummyBath)["(Intercept)"] + coef(modelSBedDummyBath)["size"] * mydata$size + coef(modelSBedDummyBath)["beds2"] * 1 + coef(modelSBedDummyBath)["baths"] * mydata$baths, NA)
mydata$yHatSBedDummyBath3 <- ifelse(mydata$beds == 3 ,coef(modelSBedDummyBath)["(Intercept)"] + coef(modelSBedDummyBath)["size"] * mydata$size + coef(modelSBedDummyBath)["beds3"] * 1 + coef(modelSBedDummyBath)["baths"] * mydata$baths, NA)
mydata$yHatSBedDummyBath4 <- ifelse(mydata$beds == 4, coef(modelSBedDummyBath)["(Intercept)"] + coef(modelSBedDummyBath)["size"] * mydata$size + coef(modelSBedDummyBath)["beds4"] * 1 + coef(modelSBedDummyBath)["baths"] * mydata$baths, NA)
ggplot(mydata) +
geom_point(aes(y=price,x=size, col=factor(beds)), shape = 4) + scale_color_manual(values=c("red", "orange", "green","blue")) +
geom_point(aes(y=yHatSBedDummyBath1,x=size), col = "red") +
geom_point(aes(y=yHatSBedDummyBath2,x=size), col = "orange") +
geom_point(aes(y=yHatSBedDummyBath3,x=size), col = "green") +
geom_point(aes(y=yHatSBedDummyBath4,x=size), col = "blue") +
geom_abline(intercept=coef(modelSBedDummyBath)["(Intercept)"] + coef(modelSBedDummyBath)["beds2"]*0 + coef(modelSBedDummyBath)["beds3"]*0 + coef(modelSBedDummyBath)["beds4"]*0 + coef(modelSBedDummyBath)["baths"]*1,slope=coef(modelSBedDummyBath)["size"], col = "red") +
geom_abline(intercept=coef(modelSBedDummyBath)["(Intercept)"] + coef(modelSBedDummyBath)["beds2"]*0 + coef(modelSBedDummyBath)["beds3"]*0 + coef(modelSBedDummyBath)["beds4"]*0 + coef(modelSBedDummyBath)["baths"]*2,slope=coef(modelSBedDummyBath)["size"], col = "red") +
geom_abline(intercept=coef(modelSBedDummyBath)["(Intercept)"] + coef(modelSBedDummyBath)["beds2"]*1 + coef(modelSBedDummyBath)["beds3"]*0 + coef(modelSBedDummyBath)["beds4"]*0 + coef(modelSBedDummyBath)["baths"]*1,slope=coef(modelSBedDummyBath)["size"], col = "orange") +
geom_abline(intercept=coef(modelSBedDummyBath)["(Intercept)"] + coef(modelSBedDummyBath)["beds2"]*1 + coef(modelSBedDummyBath)["beds3"]*0 + coef(modelSBedDummyBath)["beds4"]*0 + coef(modelSBedDummyBath)["baths"]*2,slope=coef(modelSBedDummyBath)["size"], col = "orange") +
geom_abline(intercept=coef(modelSBedDummyBath)["(Intercept)"] + coef(modelSBedDummyBath)["beds2"]*0 + coef(modelSBedDummyBath)["beds3"]*1 + coef(modelSBedDummyBath)["beds4"]*0 + coef(modelSBedDummyBath)["baths"]*1,slope=coef(modelSBedDummyBath)["size"], col = "green") +
geom_abline(intercept=coef(modelSBedDummyBath)["(Intercept)"] + coef(modelSBedDummyBath)["beds2"]*0 + coef(modelSBedDummyBath)["beds3"]*1 + coef(modelSBedDummyBath)["beds4"]*0 + coef(modelSBedDummyBath)["baths"]*2,slope=coef(modelSBedDummyBath)["size"], col = "green") +
geom_abline(intercept=coef(modelSBedDummyBath)["(Intercept)"] + coef(modelSBedDummyBath)["beds2"]*0 + coef(modelSBedDummyBath)["beds3"]*0 + coef(modelSBedDummyBath)["beds4"]*1 + coef(modelSBedDummyBath)["baths"]*1,slope=coef(modelSBedDummyBath)["size"], col = "blue") +
geom_abline(intercept=coef(modelSBedDummyBath)["(Intercept)"] + coef(modelSBedDummyBath)["beds2"]*0 + coef(modelSBedDummyBath)["beds3"]*0 + coef(modelSBedDummyBath)["beds4"]*1 + coef(modelSBedDummyBath)["baths"]*2,slope=coef(modelSBedDummyBath)["size"], col = "blue")## Warning: Removed 184 rows containing missing values (`geom_point()`).## Warning: Removed 150 rows containing missing values (`geom_point()`).## Warning: Removed 148 rows containing missing values (`geom_point()`).## Warning: Removed 166 rows containing missing values (`geom_point()`).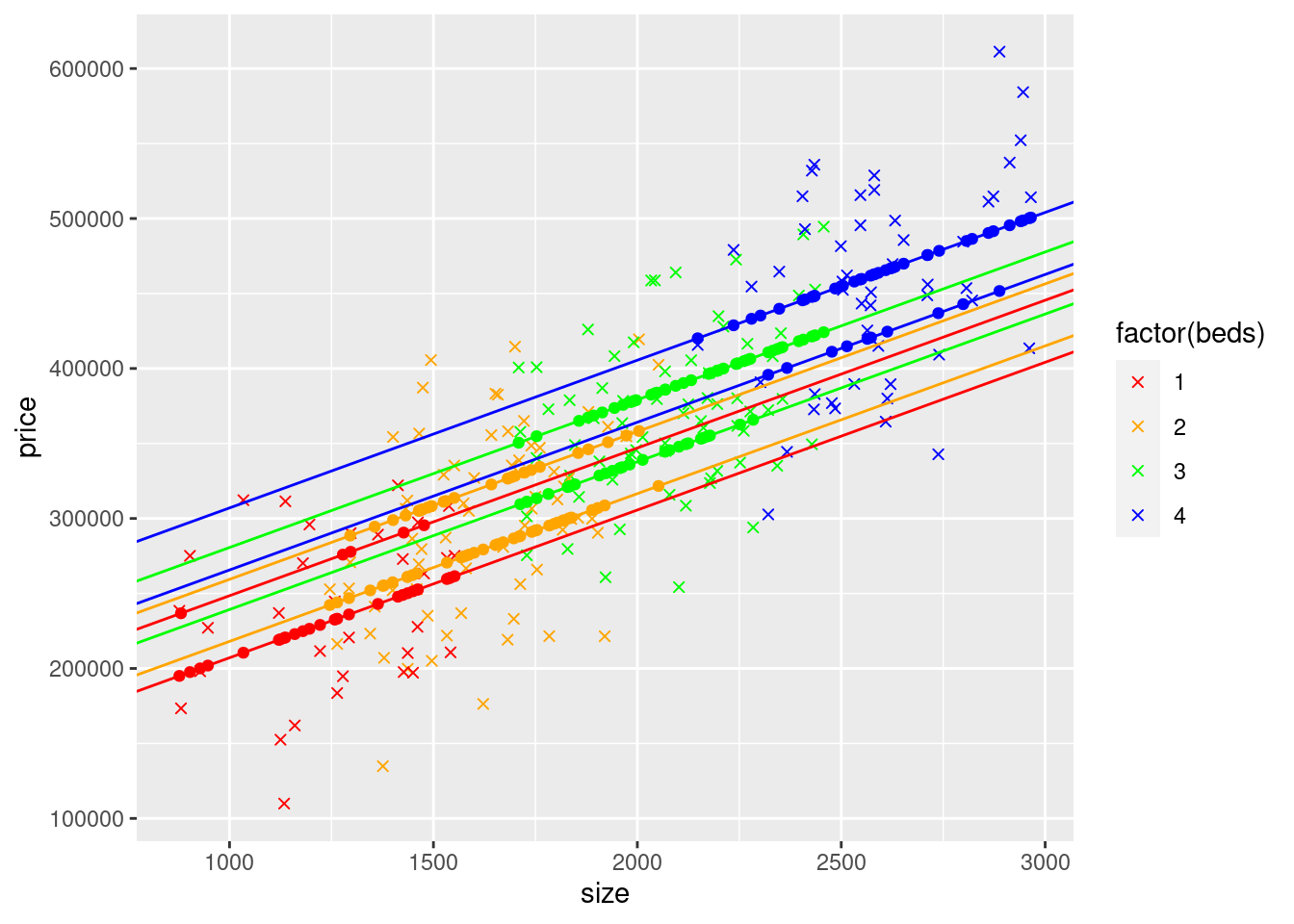
Because we allowed for each of the Dummy Variables for bed to be calculated such that they reflect the difference in price between a house with 2 3 or 4 beds and a house with 1 bed, given the same number of \(ft^2\) separate from each other, will be spaced apart by different amounts, given the number of baths is held constant. Since there are only 2 possible values for baths, the space between the 2 lines of the same number of bedrooms will be the same no matter what number of bedrooms you compare.